
[AIOT] project using AI speech synthesis
Discover the forefront of AIOT with AI speech synthesis. Merging WIZnet IoT speaker tech with AI TTS, experience real-time audio delivery.


WIZnet - W5300
x 1
Python - Python
x 1
Overview
Voice technology has many applications in the modern world. Consumers have come to expect voice interactions in smartphones, home devices, and services. In addition, a project that uses AI to learn the voices of popular singers to recreate their songs has recently attracted attention. Based on these trends, we have started a new project using WIZnet IoT speaker with AI TTS technology and singer voice recreation technology.
* The following is the original description, not mine. I used it because it is more descriptive.*
Requirements
- Organize the requirements to achieve the goal and define and schedule detailed tasks based on them.
- Utilize the high-speed characteristics of the W5300 chip.
- Be able to deliver audio data in real time.
- It should be able to output data from the network to the speaker.
- It should be possible to check necessary information such as IP using an information display device such as an LCD.
- Build own board and share the data.
- Audio data can be sent from a PC or to the same board.
- The development environment must be multiplatform. (Windows/Mac/Linux)
- W5300 Control reads datasheets and uses registers to build libraries by hand.
Considerations
- As you progress through the project, feel free to draw out and reflect on things to consider.
- I make my own boards and enjoy the process.
- Create additional I/O on the board beyond the basic functions so that it can be utilized as a development board.
- How do you want to send audio data from the PC?
- If you're creating a PC program, should it be a GUI?
- Do I need a microphone sensor, and if so, should I mount it on the board?
- Can we send video data as well?
- Could you send motion data to control a remote robot?
Hardware
- Schematic and Artwork Online with EasyEDA
- SMT directly through JLCPCB
Firmware
- Build Environments
- CMake, GCC, Make
- Editing Tools
- Visual Studio Code
- Libraries
- STM32CubeH7
- MCU library provided by ST
- LittleFS
- File system for embedded with failsafe features
- LVGL
- Free GUI library for embedded use
- WIZnet ioLibrary_Driver
- dhcp, sntp, socket
- STM32CubeH7
- MCU code generator
- STM32CubeMX
Software
- PySide6
- A Python version of Qt6
- MinGW GCC
- For creating PC programs to update firmware
Basic Specifications
Specifications
| Item | Item name | Specification | Remarks |
|---|---|---|---|
| MCU | STM32H723ZGT6 | FLASH : 1MB, SRAM : 564KB | External SRAM bus 16-bit |
| Ext. FLASH | W25Q128JVSIQTR | 16MBytes | For firmware updates, data storage |
| Network | W5300 | 16bit bus | |
| Audio H/W #1 | MAX98357A | I2S Codec/AMP | Connect to Speakers |
| Audio H/W #2 | ES8156 | I2S Codec | Connect to AMP |
| Buzzer | |||
| LCD | 1.3인치 IPS | 240x240 | https://ko.aliexpress.com/item/33021695448.html |
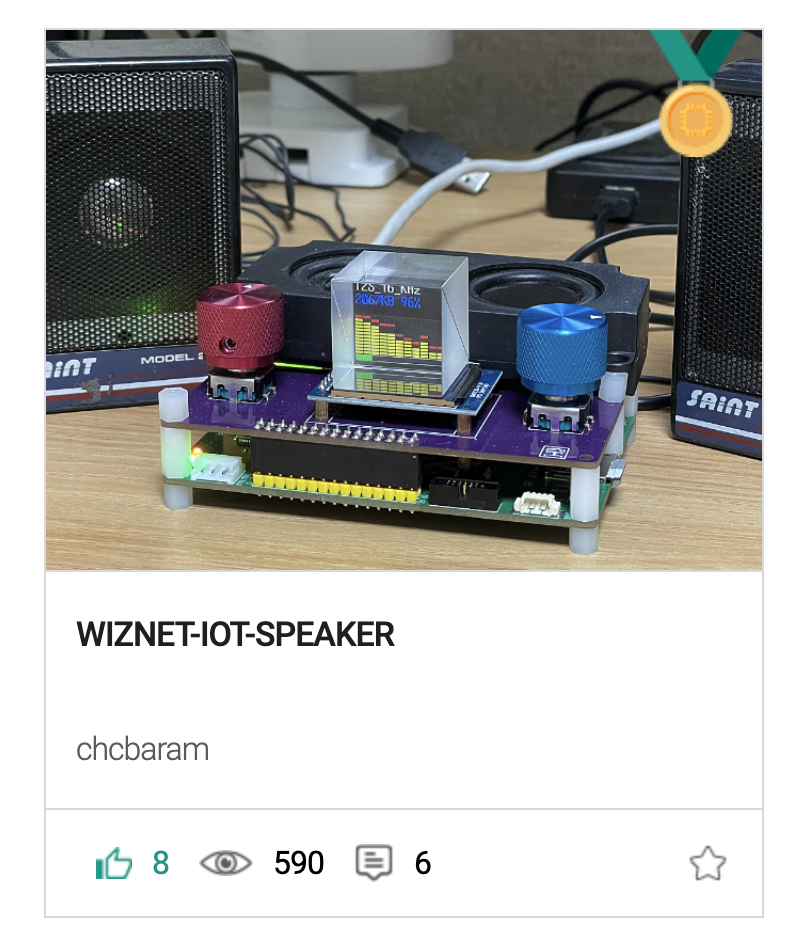
W5300 Development Process
- chobaram made a custom board utilizing the w5300 chip to carry out the project. The w5300 was based on the reference schematic and separated the digital and analog in the power configuration, but we did not separate them and used them in common. The external clock is 25Mhz and when you give a 3.3V input, a 1.8V voltage is output, and he connected it to the pins that require 1.8V.
- The clock used an oscillator and when you use an oscillator you need to use 1.8V for power.
- For the Ethernet connector, they chose a type with a built-in transformer, but in order to find a connector pin arrangement that does not twist when connected to the signal lines of the chip, they found several models and used parts that do not use vias as much as possible.
- In order to use the 16-bit bus mode, the BIT16EN pin must be HIGH, but there is a pull-up inside the chip, so it is said that it can be used as a 16-bit bus if it is opened.
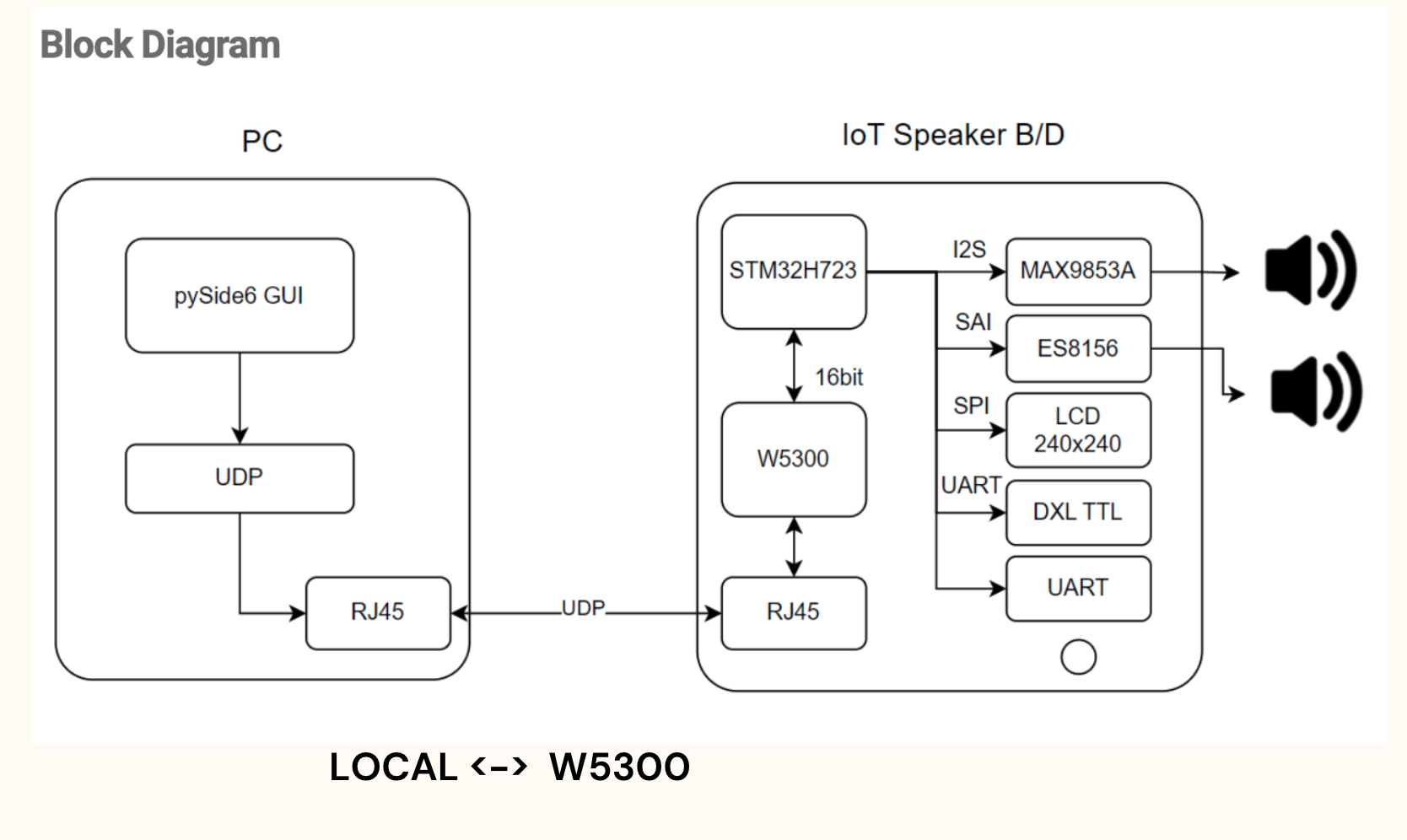
- 16-bit data bus: The W5300's data registers are 16 bits wide, which allows the MCU to read or write 16 bits of data in a single operation.
- Address bus: The address bus allows the MCU to select and access specific registers within the W5300
- Control signals: Control signals such as RD, WR, and CS allow the MCU to control data read/write operations with the W5300.
- Interrupts: The W5300 issues interrupts to the MCU on certain network events (e.g., data arrival, connection establishment, etc.), requesting that the event be handled.
- In reality, there are several AI TTS models, such as Tacotron, but once you start training with it, it takes several days, and it is impossible or difficult to collect the data I want. So I looked for pre-trained models. On Huggerface, there are usually AI models listed, and as I was riding along, there was a place where they had collected some models on the Discord channel.
- After that, I just need to search and find the model of the singer I want and enter the link into the code window above, but when I read the code, it loads the model after preprocessing the zip file for the download file link. So if you have your own model, you can load it without preprocessing and modify the code.
- Next, Gradio allowed the coders to load the model into the GUI and then tweak the parameters.
Reference
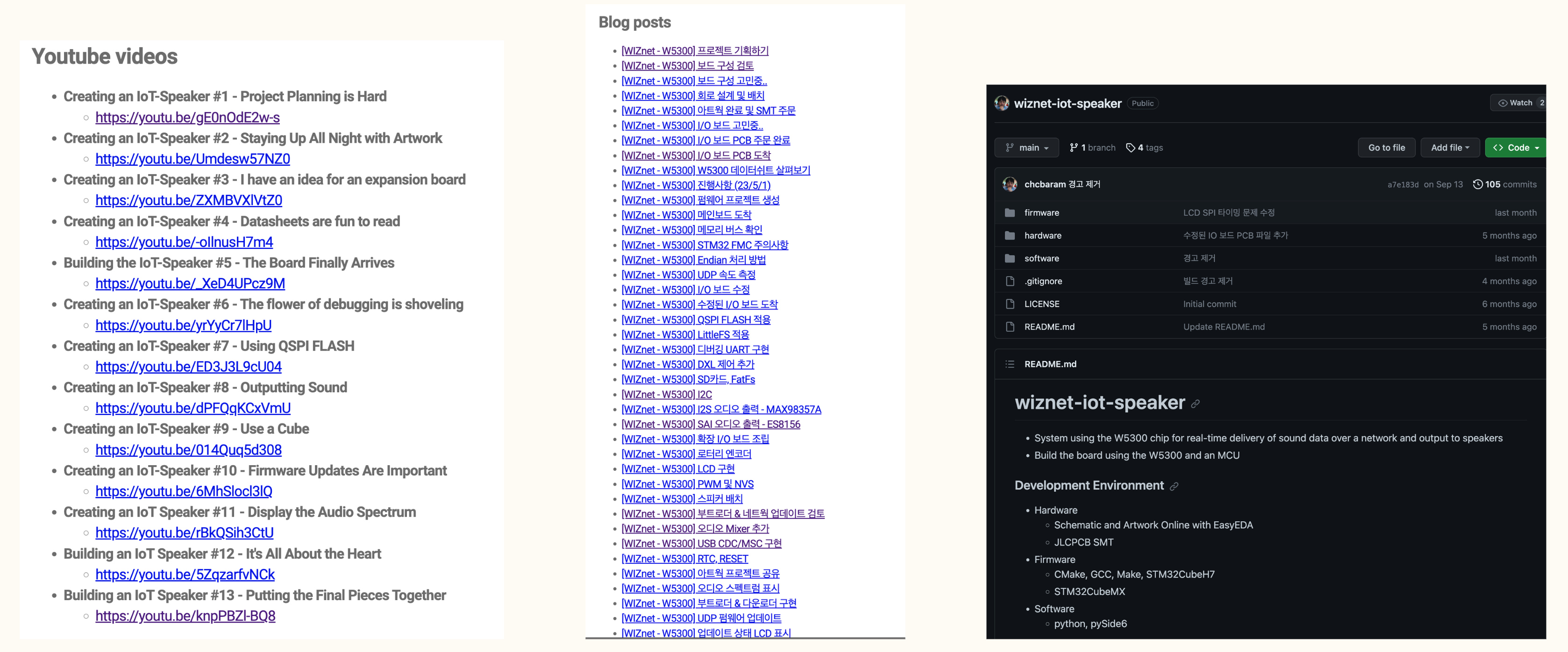
As a first place project, I have organized YouTube videos and related materials as blog posts during the implementation process, and I have organized H/W, S/W, and GUI code on github. I would like to introduce how our chip was used in the above project, and what principle and code were implemented first.
ToE Contest 1st project by chobaram
AI Solution

Requirements
- mp3 file original
- CUDA GPU or Colab Pro
- pretrained artist voice
- ChatGPT
- Bandlab
- GaudiStudio
Reference RVC v2 Colab descriptions
Making
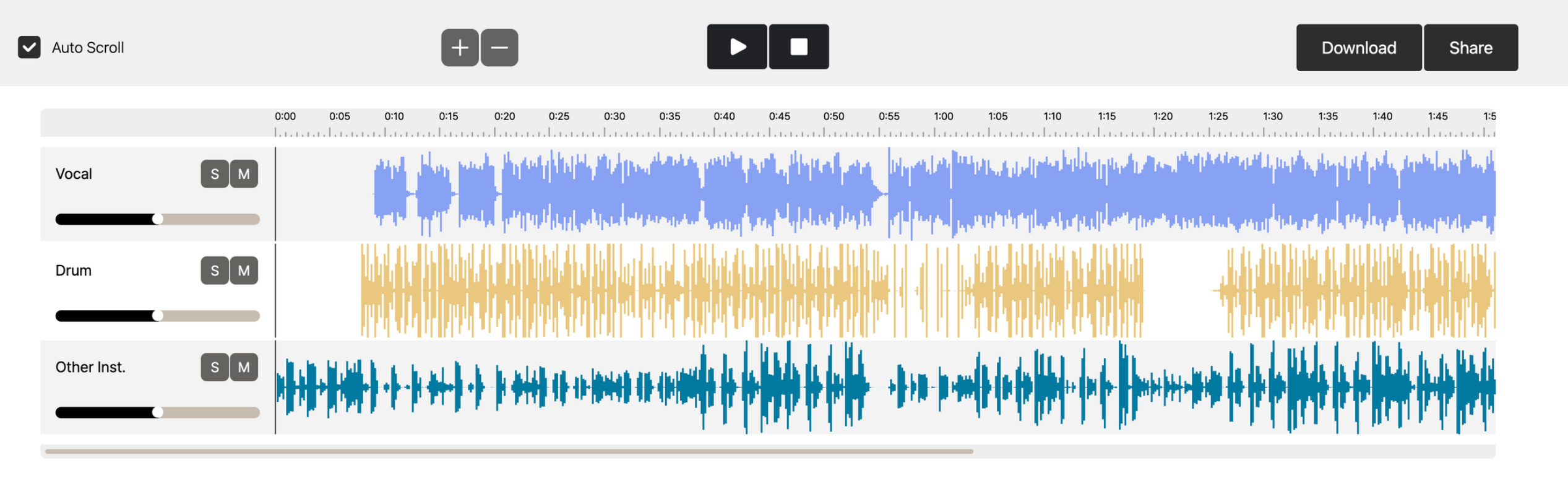
The first step is to download an MP3 file of the music you want and split the instrumental and vocals in GAUDIO STUDIO.

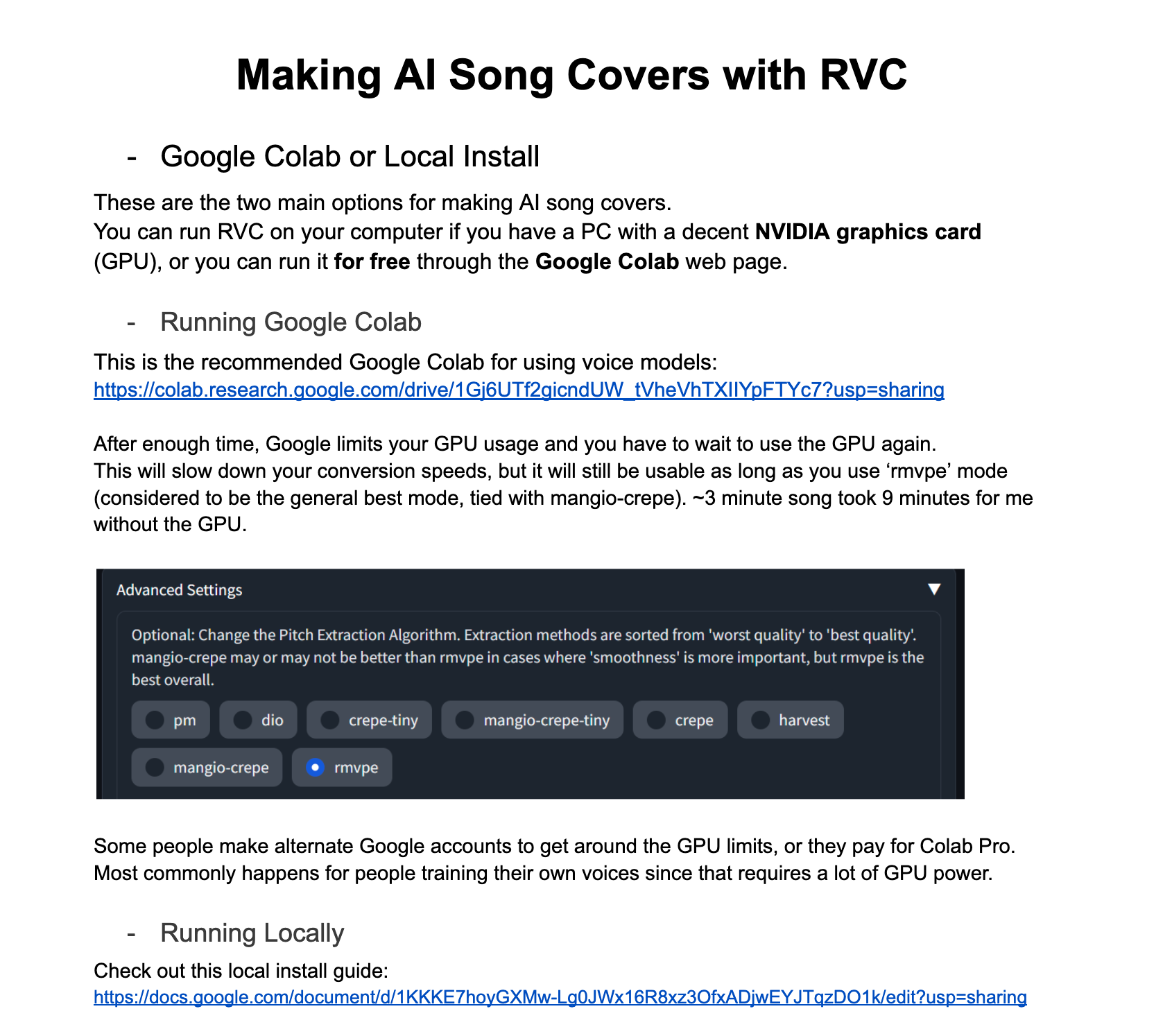
If you go to the RVC v2 docs and read through them, there are a lot of different values for hyperparameters and a lot of different source code. In fact, the author and others have done a lot of parameter tuning experiments, so it's best to use the default values.
Find a link where a trained model of the singer you want has been saved and downloaded, either from a place with a lot of AI models like Hugging Face or through a community.
You can do this by running the colab code in the RVC v2 docs straight through.
Code
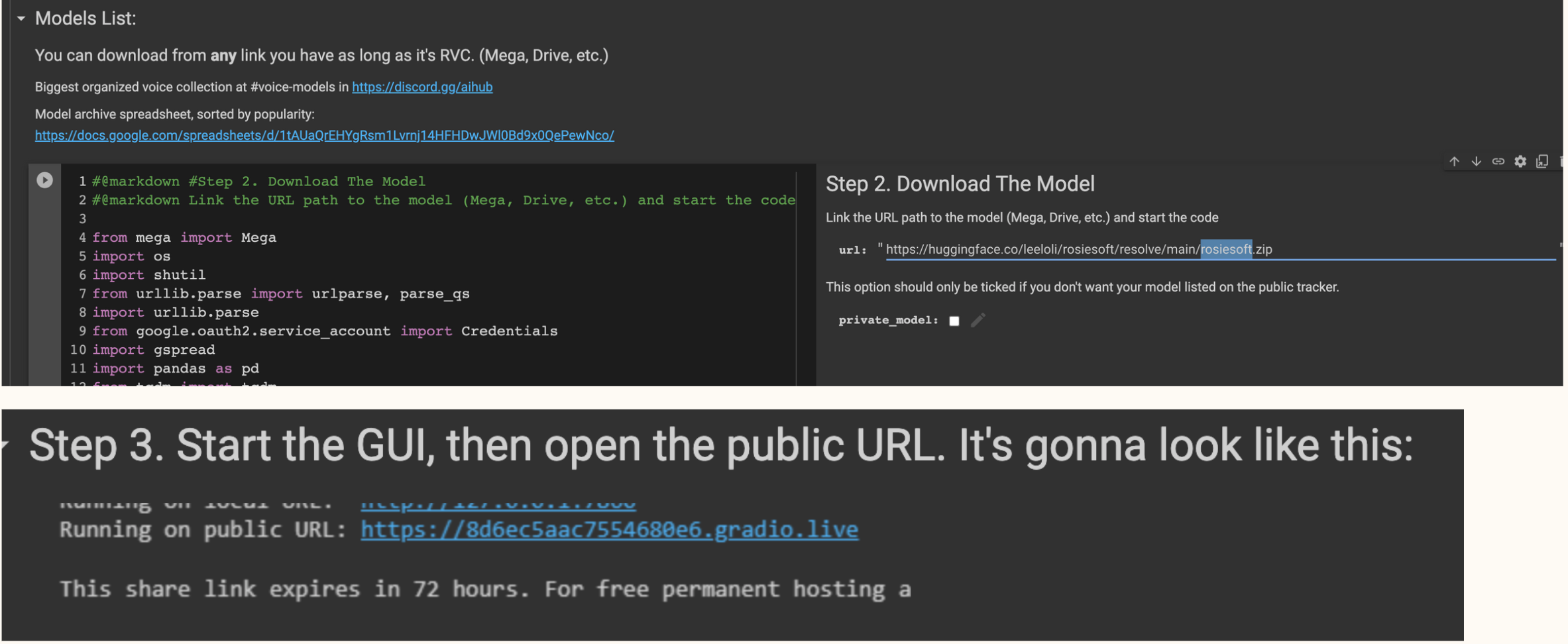
# Model load
url = 'https://huggingface.co/leeloli/rosiesoft/resolve/main/rosiesoft.zip' #@param {type:"string"}
model_zip = urlparse(url).path.split('/')[-2] + '.zip'
model_zip_path = '/content/zips/' + model_zipFind the trained model of the singer you want and put the link to the model's save location in the URL.
import os
import time
import fileinput
from subprocess import getoutput
import sys
from IPython.utils import capture
from IPython.display import display, HTML, clear_output
%cd /content/Retrieval-based-Voice-Conversion-{reeee}UI/
#@markdown Keep this option enabled to use the simplified, easy interface.
#@markdown <br>Otherwise, it will use the advanced one that you see in the YouTube guide.
ezmode = True #@param{type:"boolean"}
#@markdown You can try using cloudflare as a tunnel instead of gradio.live if you get Connection Errors.
tunnel = "gradio" #@param ["cloudflared", "gradio"]
if ezmode:
if tunnel == "cloudflared":
for line in fileinput.FileInput(f'Easier{weeee}.py', inplace=True):
if line.strip() == 'app.queue(concurrency_count=511, max_size=1022).launch(share=True, quiet=True)':
# replace the line with the edited version
line = f' app.queue(concurrency_count=511, max_size=1022).launch(quiet=True)\n'
sys.stdout.write(line)
!pkill cloudflared
time.sleep(4)
!nohup cloudflared tunnel --url http://localhost:7860 > /content/srv.txt 2>&1 &
time.sleep(4)
!grep -o 'https[^[:space:]]*\.trycloudflare.com' /content/srv.txt >/content/srvr.txt
time.sleep(2)
srv=getoutput('cat /content/srvr.txt')
display(HTML('<h1>Your <span style="color:orange;">Cloudflare URL</span> is printed below! Click the link once you see "Running on local URL".</span></h1><br><h2><a href="' + srv + '" target="_blank">' + srv + '</a></h2>'))
!rm /content/srv.txt /content/srvr.txt
elif tunnel == "gradio":
for line in fileinput.FileInput(f'Easier{weeee}.py', inplace=True):
if line.strip() == 'app.queue(concurrency_count=511, max_size=1022).launch(quiet=True)':
# replace the line with the edited version
line = f' app.queue(concurrency_count=511, max_size=1022).launch(share=True, quiet=True)\n'
sys.stdout.write(line)
!python3 Easier{weeee}.py --colab --pycmd python3
else:
!python3 infer-web.py --colab --pycmd python3This is the code for a task that utilizes the Gradio UI window to convert the model to the desired target data.
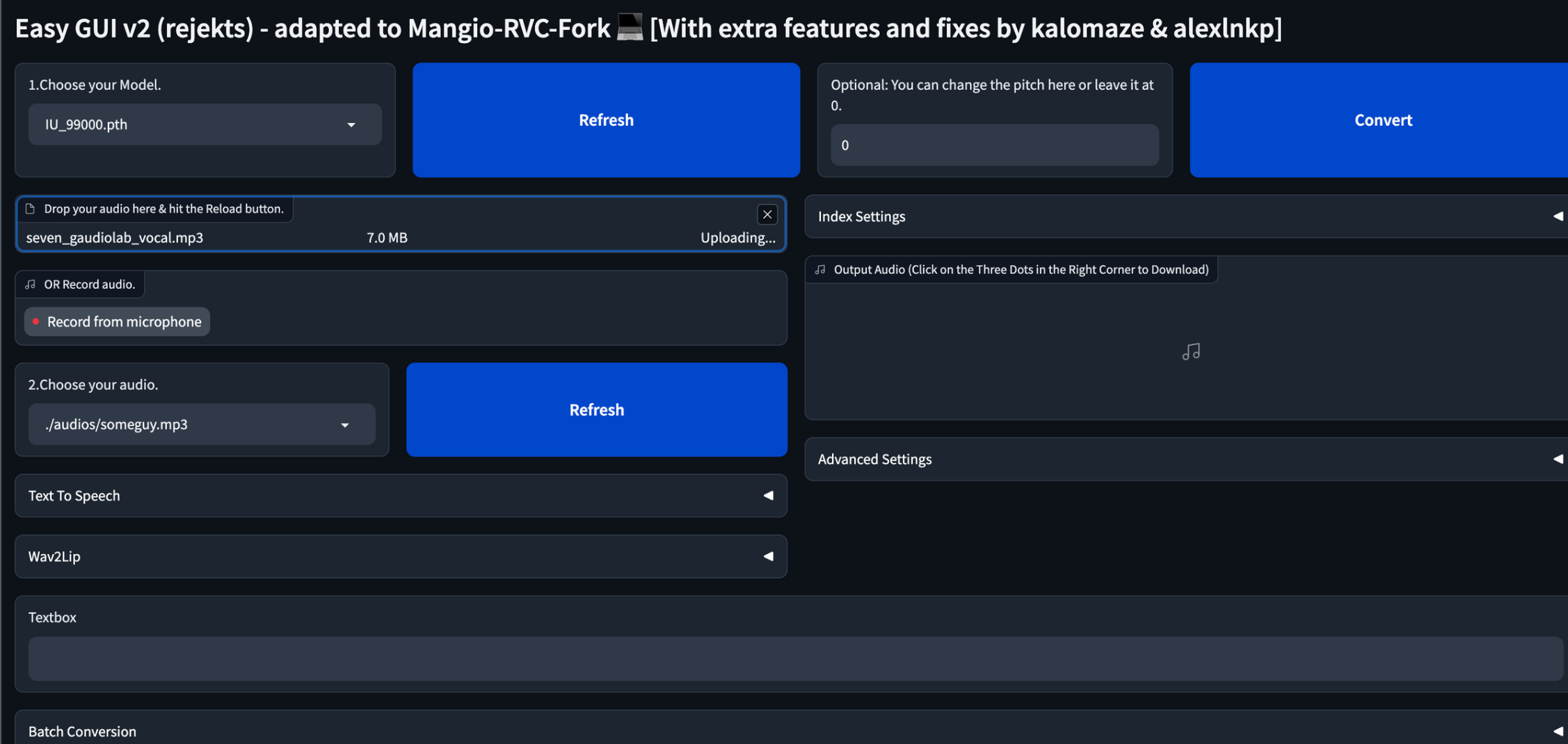
1. in Choose model, press the refresh button several times if the model with the voice of the singer you want is not loaded well.
2. You can think of it as target data, which is the vocal file you converted to gaudilab earlier. This is how I want to train the data in 1 as the target data in 2.
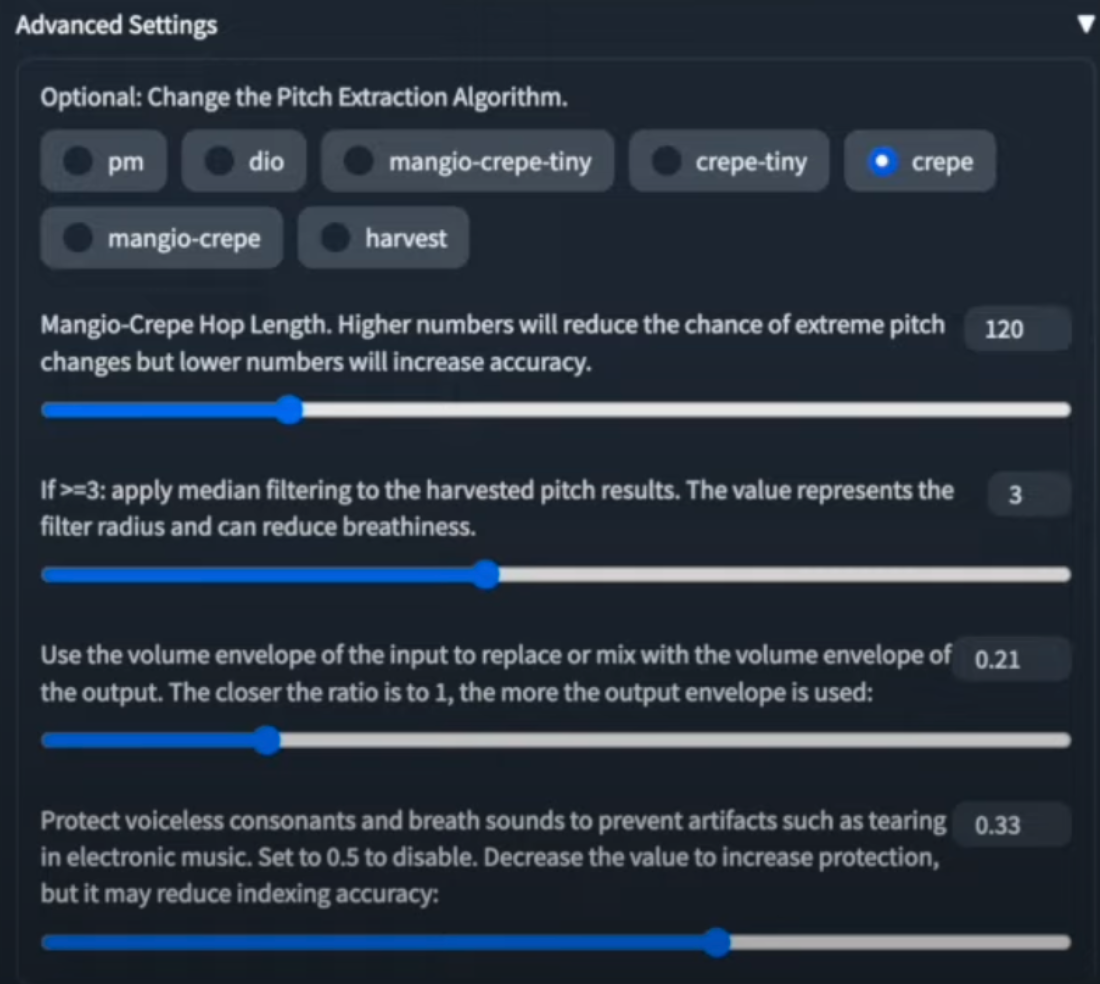
3. optional is an octave-related parameter, which changes female -> male and male -> female +-12 using the parameter. I tried it with different octaves, but it's probably better not to use it unless you have a song that needs to be changed specifically. After converting, the synthesis proceeds. The result is a vocal file.

- After the speech synthesis is completed, you can download the file and get the file. The parameters below are TTS-related parameters, but after experimenting with them, the best performance is to set them to the default values and convert them.

- After that, various instrumental elements, such as drums, which are synthesized from the previously extracted sound source and the TTS result, must be combined again in a music-related work program. There are various programs such as Ableton, Cue Bass, Logic, etc., but this is easily available to those who have used it for some time, and if you are an Apple user, Garageband is said to be very good in cost performance. And you can combine them through BandLab, which is available on the web
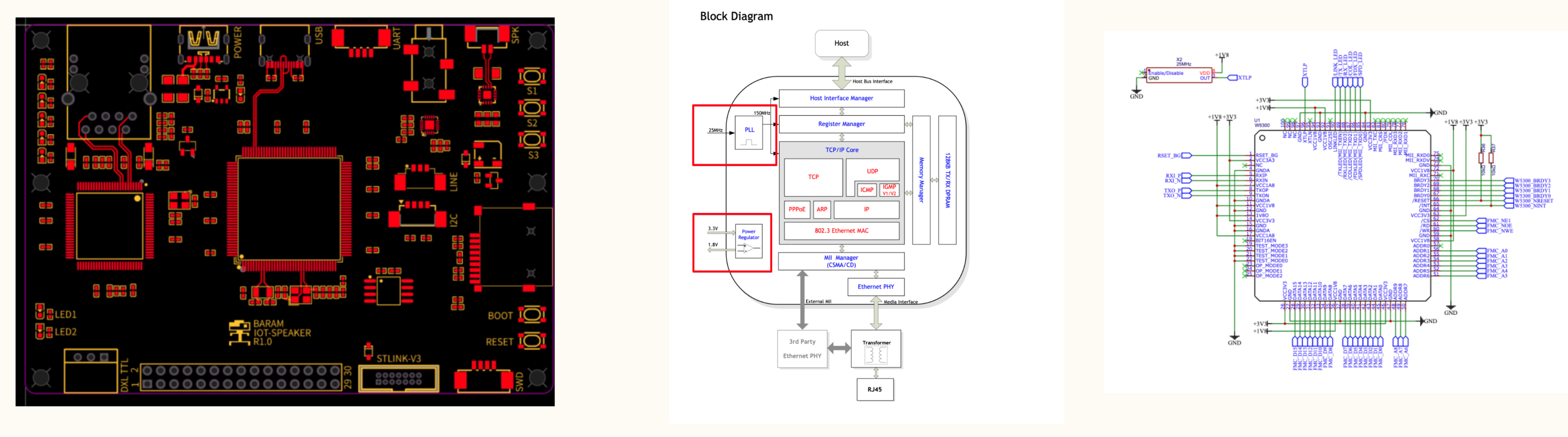
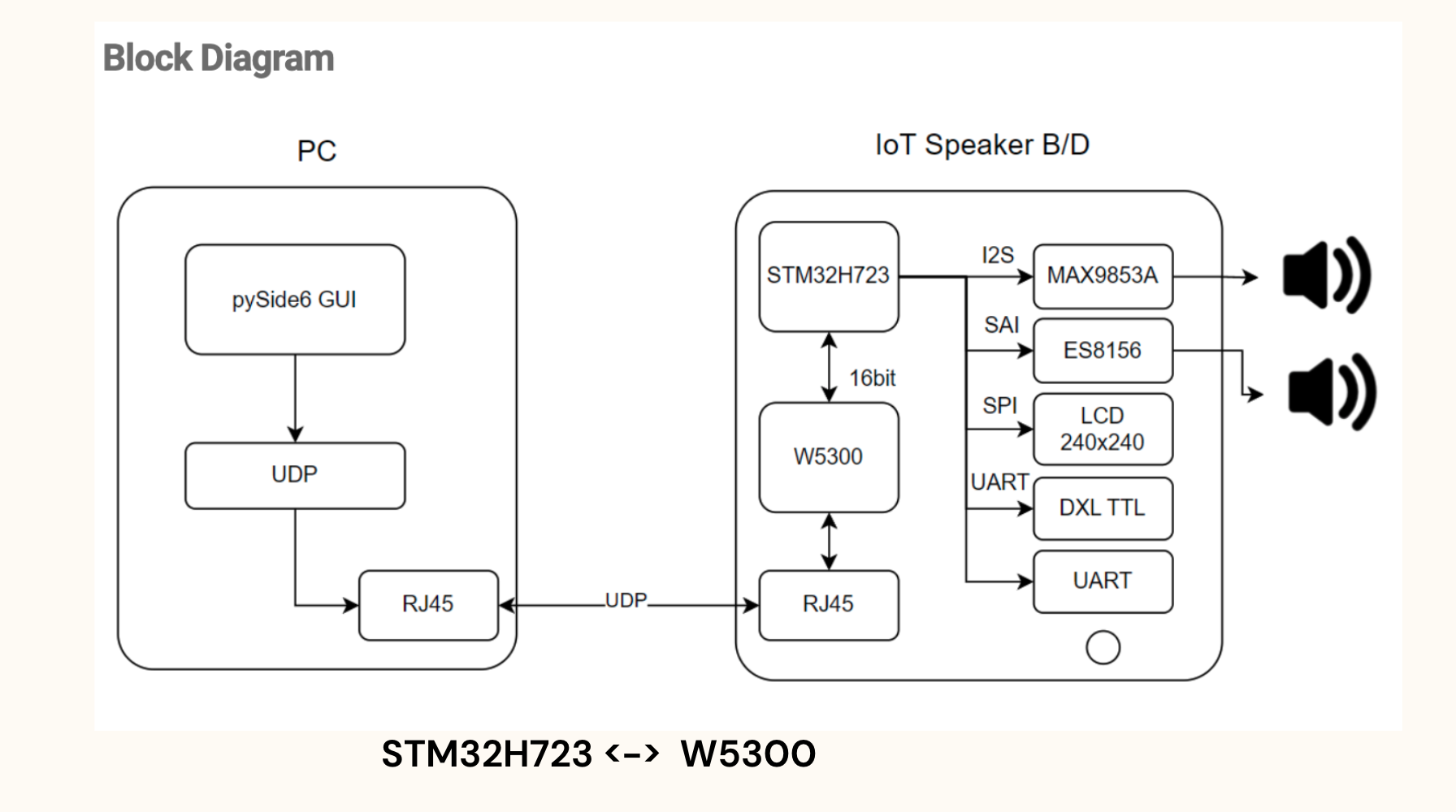
AIOT SPEAKER
Result
https://youtube.com/shorts/1VO9MiSQf1U?feature=shared Result Test

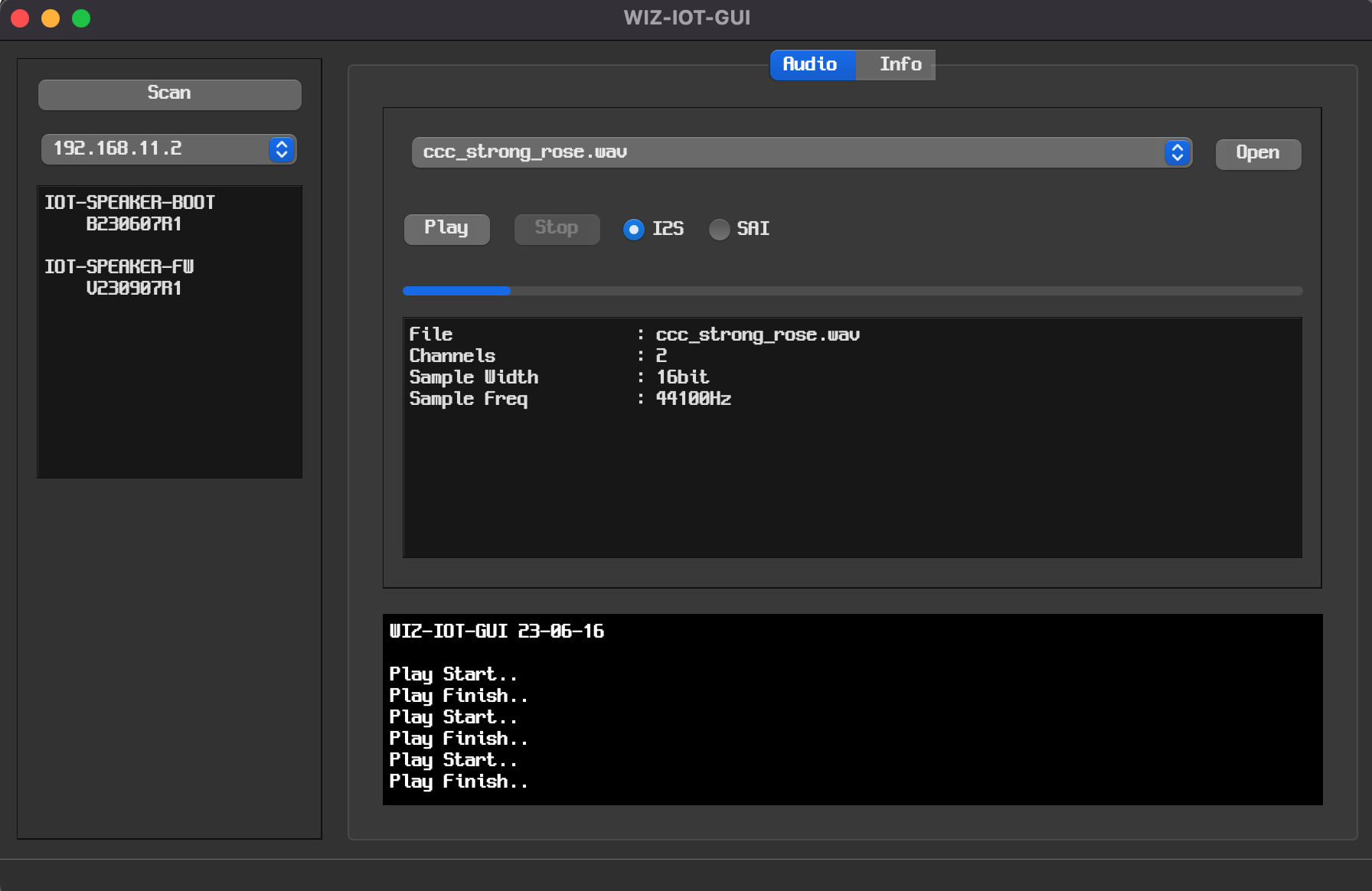
Connect the IOT SPEAKER made above to the Ethernet communication and put the voice converted by AI into the GUI program.
1. IOT Speaker first prepares for communication by setting IP.
2. When it is completed, press the Play button on the GUI program and the music will come out.
3. You can use the speaker according to the desired output format with I2S and SAI. The red button controls the volume of SAI, and the blue button controls I2S.