How to get an answer to rp2040 in 4 seconds with Groq
How to get an answer to rp2040 in 4 seconds with Groq


WIZnet - W5100S-EVB-Pico
x 1
Project Overview

If you have already done a project with Chatgpt and gemini connected to rp2040, we are going to do a project with open source model. We are going to make an innovation with meta's llama3 and groq's LPU chip announced a few days ago.
I believe it is a good enough replacement for the examples on the maker site and will allow us to upgrade our projects with faster responses. It is applicable enough for AIoT examples that require fast responses.
what is groq?
Jonathan Ross is a former Google TPU architect who is now the CEO of the Groc startup. Why it's here By creating an LPU-based chip, we've created an environment that can infer models more efficiently than nvidia.
more efficient model inference than nvidia. We have a foundry contract with Samsung, which will probably go into full-scale production, but Groq has declared that we don't sell chips. The environment of selling chips like Nvidia is difficult for a startup, and we said that we will do the process of inferring in the cloud environment. Currently, you can reference open LLM models on Groq's official website.
One of them is Lamar 3, which was released last week.

As you can see, it generates hundreds of tokens per second. It would take over 20 seconds to create a sentence with that many tokens with traditional ChatGPT.
What is LLaMA3?

Lama 3 was released just last Friday, and its current benchmarks are also comparable to GPT-4. The 8B model outperforms GPT3.5 and the 70B is comparable to gpt-4. This is a model trained on 24T pairs of clustered GPUs. This is BigTech, so you can see that it is possible to train with astronomically ridiculous GPUs. I don't know the details because the paper is not publicly available, but I read and reviewed Lama3, so if you are curious, you can read it on the Wiznet Tech blog.
Project Tutorial
1. Enter the groq cloud homepage, sign up, get an API KEY, and run the python code next to it. It would be nice if the groq library is installed, but of course, we can't install the library in pico, so we have to run the code through API communication.
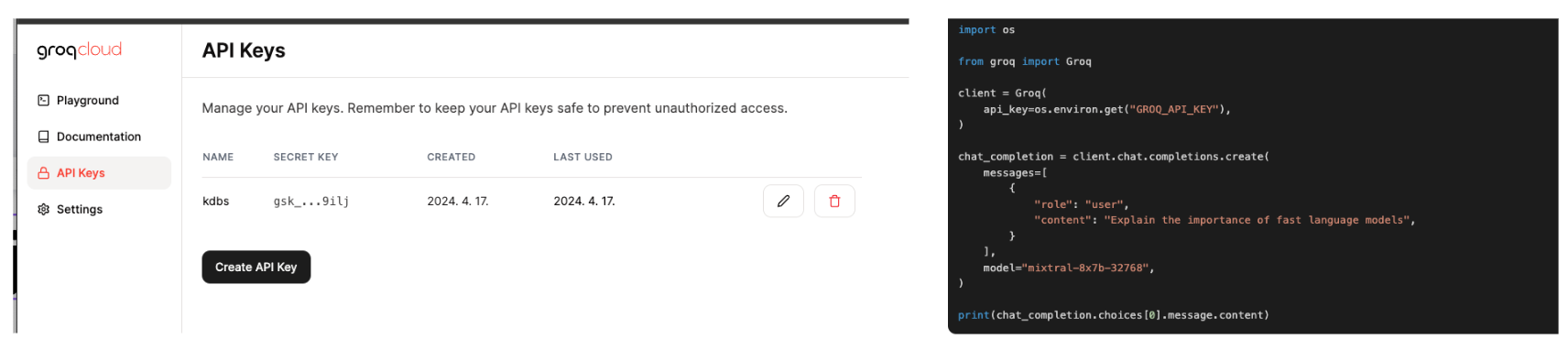
2. It's not hard to get and read the curl code: you just need to define the endpoint, header settings, and how to send the data. In Micro Python, the code looks like the above. In the model part, you can set the model name llama3 in Docs.


def send_chat_request(api_key, user_message):
url = "https://api.groq.com/openai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"messages": [{"role": "user", "content": user_message}],
"model": "llama3-70b-8192"
}
start_time = utime.ticks_ms() # start time
response = urequests.post(url, headers=headers, json=payload)
elapsed_time = utime.ticks_diff(utime.ticks_ms(), start_time)
if response.status_code == 200:
try:
content = response.json()['choices'][0]['message']['content']
return content, elapsed_time # 내용과 처리 시간 반환
except Exception as e:
raise Exception("Failed to decode JSON from response: " + str(e))
else:
raise Exception(f"API error ({response.status_code}): {response.reason}")I implemented it through app.py. The init_ethernet function is to initialize the Ethernet, enter the api key in the main function, initialize the Ethernet, and start the interactive response chat through the While statement. This is the end of it.
from machine import Pin, SPI
import network
import utime
import urequests
def init_ethernet(timeout=10):
spi = SPI(0, 2_000_000, mosi=Pin(19), miso=Pin(16), sck=Pin(18))
nic = network.WIZNET5K(spi, Pin(17), Pin(20))
nic.active(True)
start_time = utime.ticks_ms()
while not nic.isconnected():
if (utime.ticks_diff(utime.ticks_ms(), start_time) > timeout * 1000):
raise Exception("Ethernet connection timed out.")
utime.sleep(1)
print('Connecting ethernet...')
print(f'Ethernet connected. IP: {nic.ifconfig()}')
def send_chat_request(api_key, user_message):
url = "https://api.groq.com/openai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"messages": [{"role": "user", "content": user_message}],
"model": "llama3-70b-8192"
}
start_time = utime.ticks_ms() # 시작 시간 기록
response = urequests.post(url, headers=headers, json=payload)
elapsed_time = utime.ticks_diff(utime.ticks_ms(), start_time) # 경과 시간 계산
if response.status_code == 200:
try:
content = response.json()['choices'][0]['message']['content']
return content, elapsed_time # 내용과 처리 시간 반환
except Exception as e:
raise Exception("Failed to decode JSON from response: " + str(e))
else:
raise Exception(f"API error ({response.status_code}): {response.reason}")
def main():
api_key = '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'
init_ethernet()
while True:
user_input = input("User: ").strip()
if user_input.lower() == "exit":
print("Exiting...")
break
elif not user_input:
continue
try:
response_content, time_taken = send_chat_request(api_key, user_input)
print(f"LLaMA Response: {response_content} (Processed in {time_taken} ms)") # 내용과 시간 출력
except Exception as e:
print("Error: ", e)
if __name__ == "__main__":
main()I added start_time = utime.ticks_ms() to the function to record the number of ticks. It takes only 4-5 seconds before the API call. That's a saving of 2-3 times the time it takes Gemini or gpt to call the API. It also responds well to English prompts for information. Korean is still a problem that the model needs to be trained through additional fine-tuning.
result