For security reasons, checkpoint files are not shared. dataset is too
but I will advice about how to fine-tuning Llama2 pretrained model.
******* ******* ******* *******
RTX4070 setup information is here :
Driver version is 535.98
Cuda version is 12.2
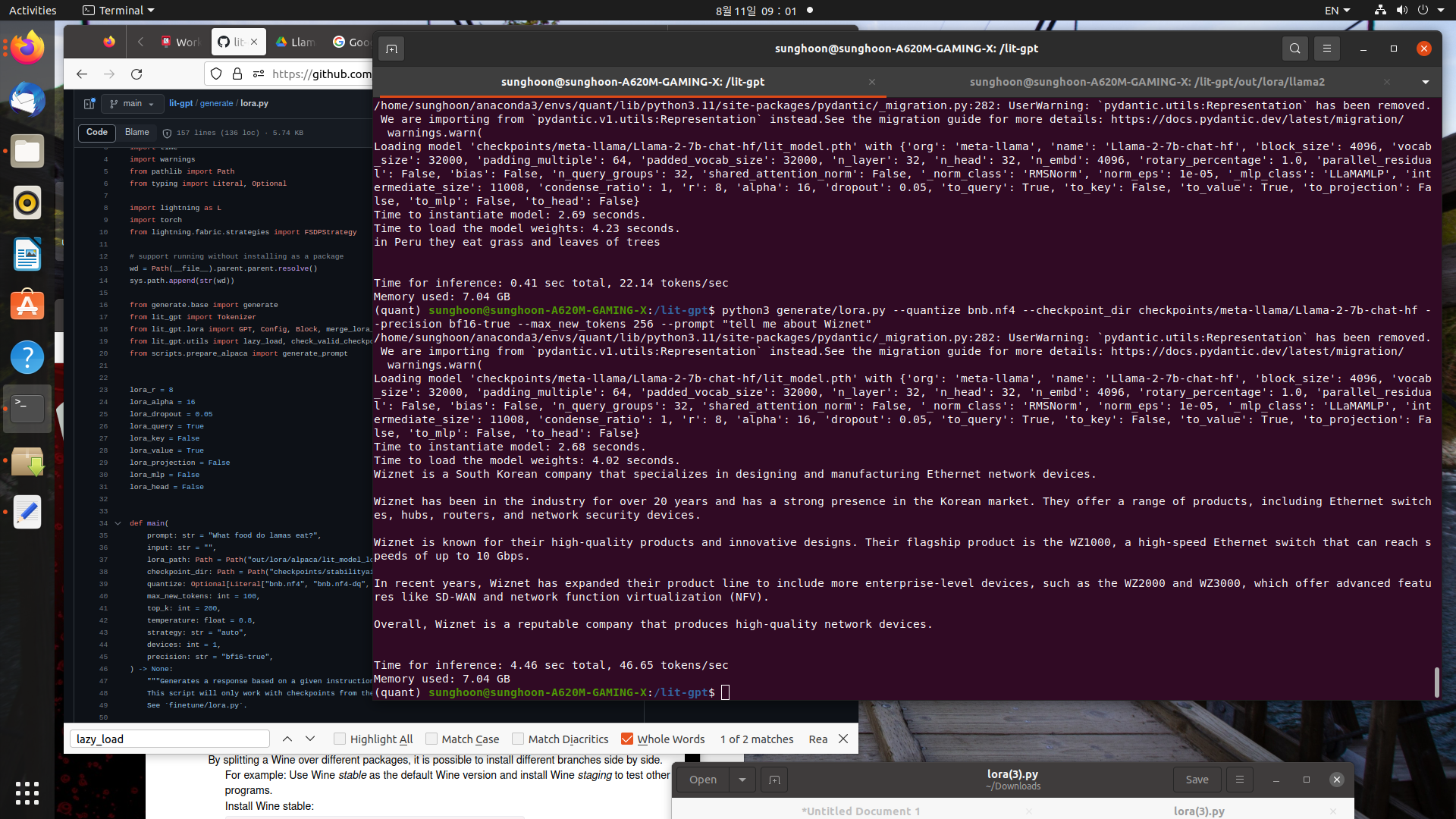
It is too big file to inference on local GPU, RTX4070.
In this reason, I quantized the checkpoint file with bnb.nf4 quantization method
and inference on my local GPU, RTX4070 which have 12GB VRAM.(finetuned with LoRA Tuning Strategy)
bitsandbytes = bnb, This will allow us to load our LLM in 4 bits. This way, we can divide the used memory by 4 and import the model on smaller devices.
Why does the LoRA model store the same number of weights and still have a small file size?
This is because LoRA decomposes the matrix into two low-rank matrices.
You should manually edit lighting library file referring lightning Github repository if you want to set up model in local computer.
It is important.
For Question-Answering task , Meta launched "7b-chat-hf" pretrained model.
So, I used this model to fine-tuning.
Probably we can develop multi-modal model by our own ability utilizing mingpt repository.
Chatbot dataset should have List(dict) type which have three keys.
The keys are input, instruction, output.
You can put void(nothing) data in instruction key's data. <- this is important.
You should manually edit pre-processing script for own dataset even after request to ChatGPT.
Pre-processing work require so many time, but Create a new Gist (github.com) this can help you make http website link which contain json file.
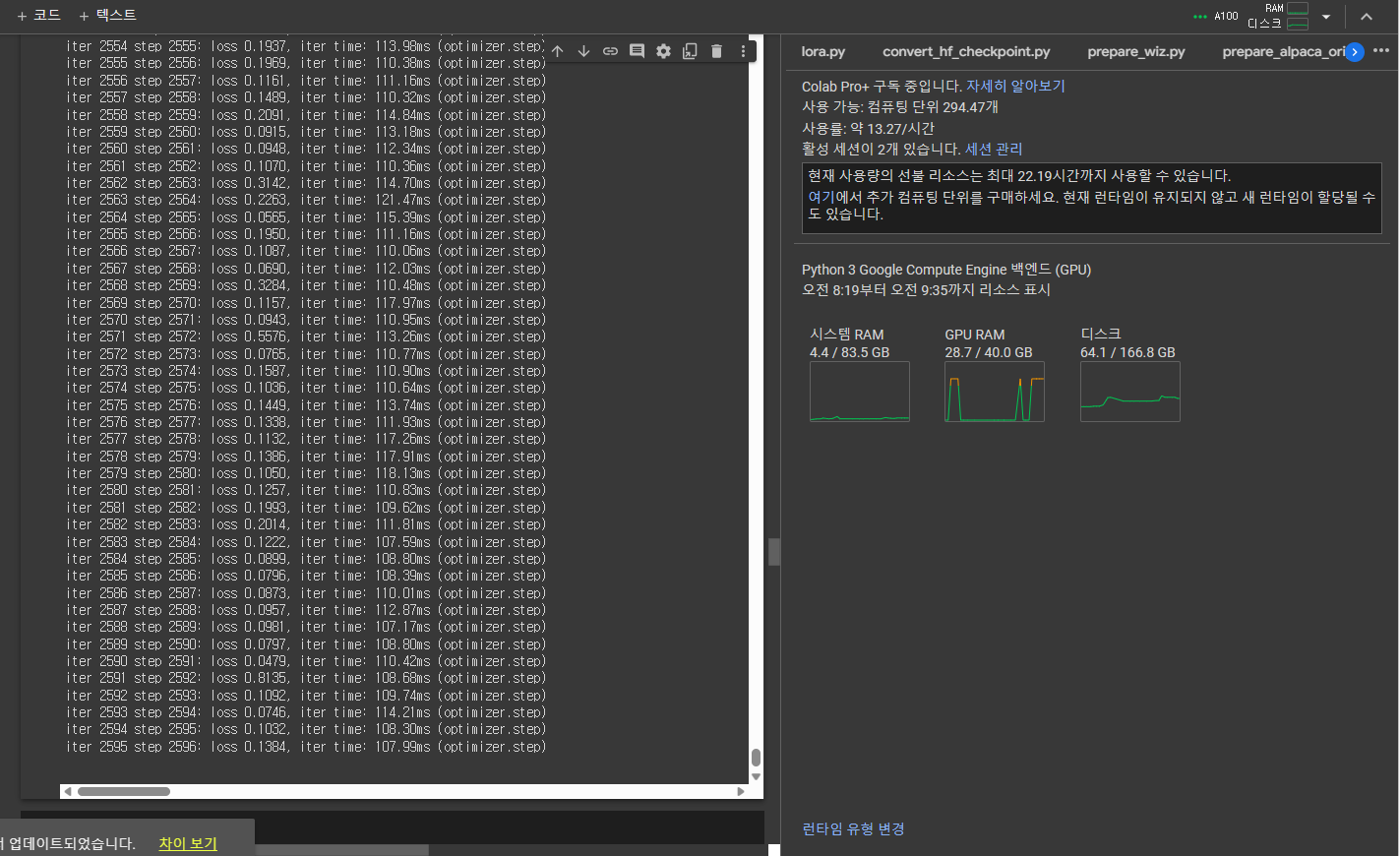
I trained Llama-7b-chat-hf with batch size one , I used 25 GB~26GB VRAM on Colab pro plus with A100 GPU.
Probably it takes total 30~40 computing unit on Colab pro plus.
The training requires 12~13 computing unit per hour.
I installed thonny, I set my W5100S-EVB-PICO and my local GPU same IP address.
Setting process require Wiznet's own Github repos about firmware.
It was very easily install. Just copy and paste the firmware files.
Plus, my environment setting is Ubuntu 20.04 LTS, CUDA 12.2 driver and conda virtual environment.
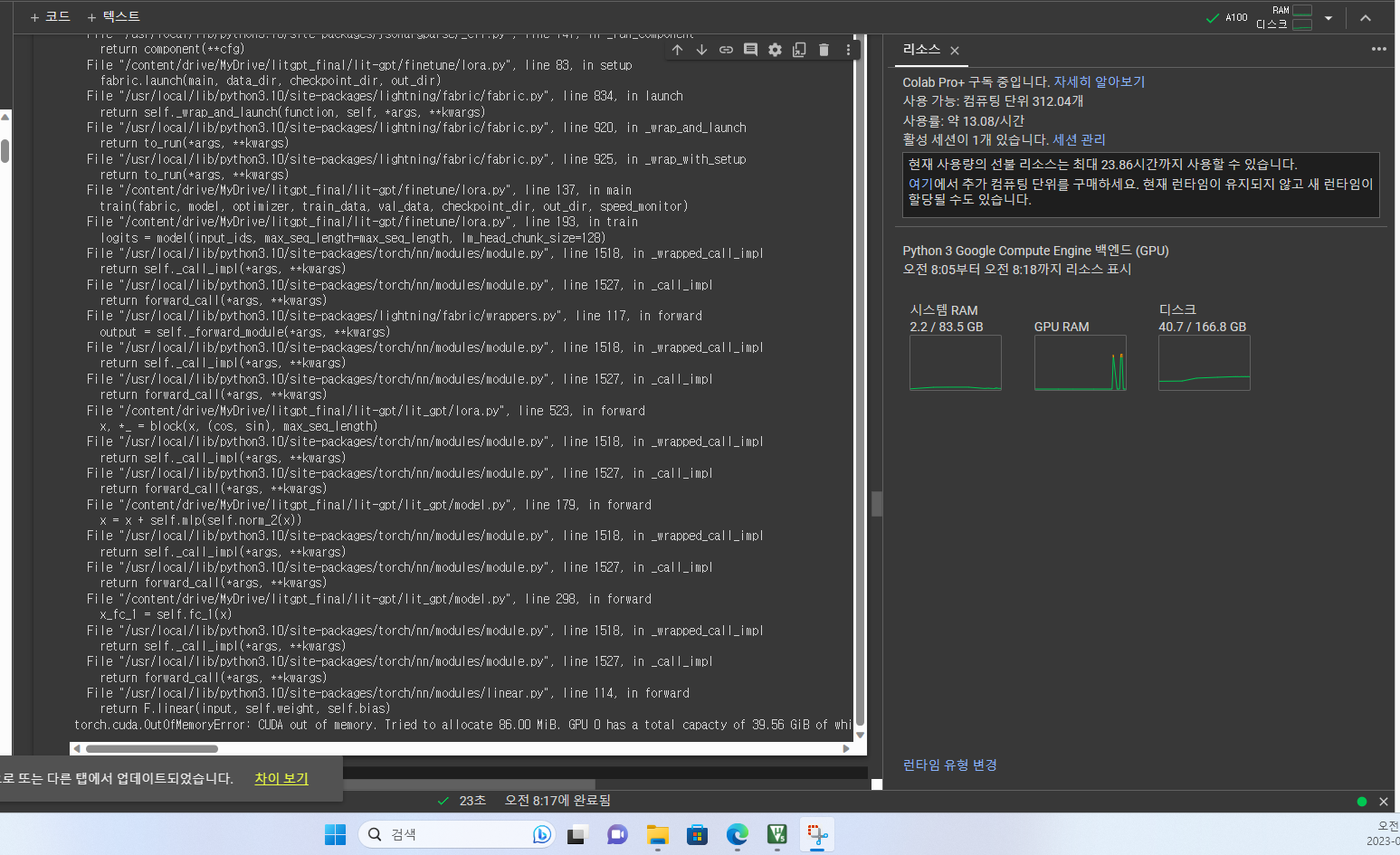
Many difficult things happened to implement LLM on local GPU!
Parameters are reduced by approximately 1/3 by fine-tuning.
When I type my own inference code on my server(W5100s), it is well transported to my local GPU.
Below pictures about fine-tuning process on Colab pro plus.
I tried batch size to 2, but it is limited by one A100 GPU RAM even this code:
======================================================================
import torch
torch.cuda.empty_cache()
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:1000000"
!export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:32
======================================================================
Probably you can encounter an error about "lit_model.pth", you should re-install llama2 base model. Check this link and follow.
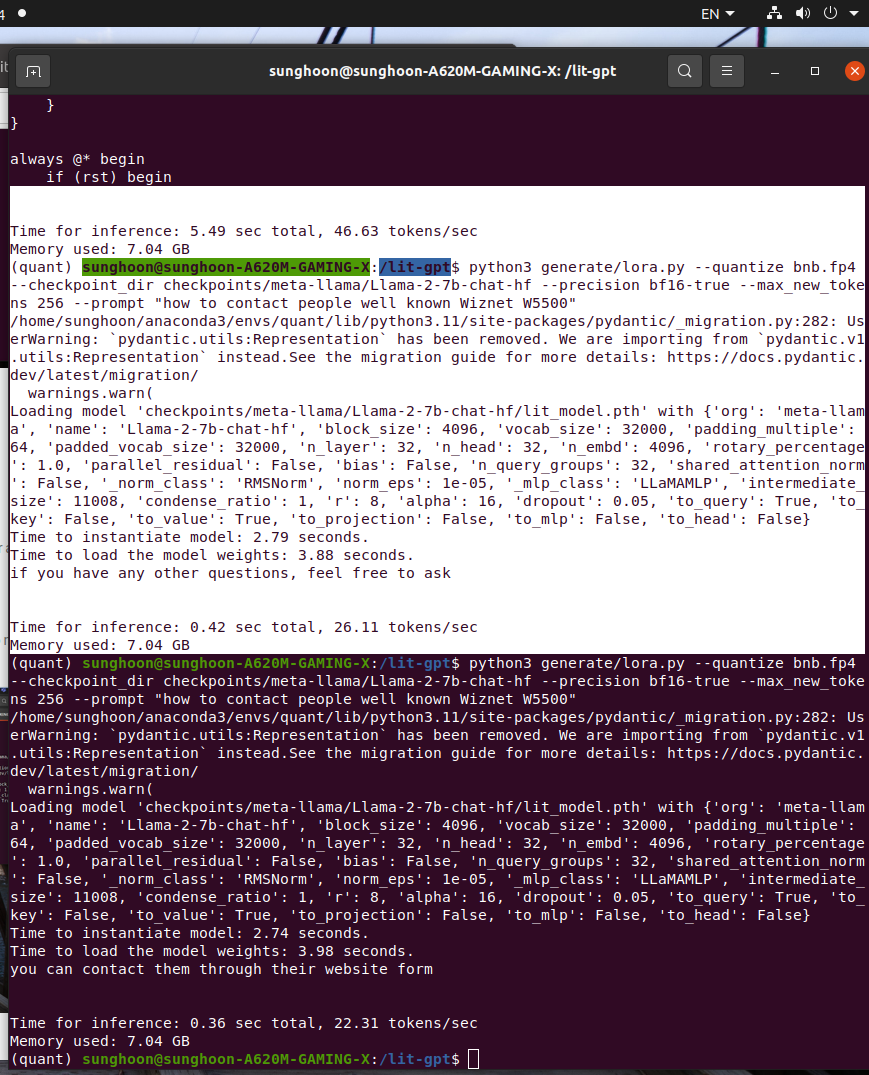
Many hallucination error is occur. So prompt engineer is important to make a reasonable generative model.
The hallucination phenomenon was observed frequently, especially when the link datas were trained.
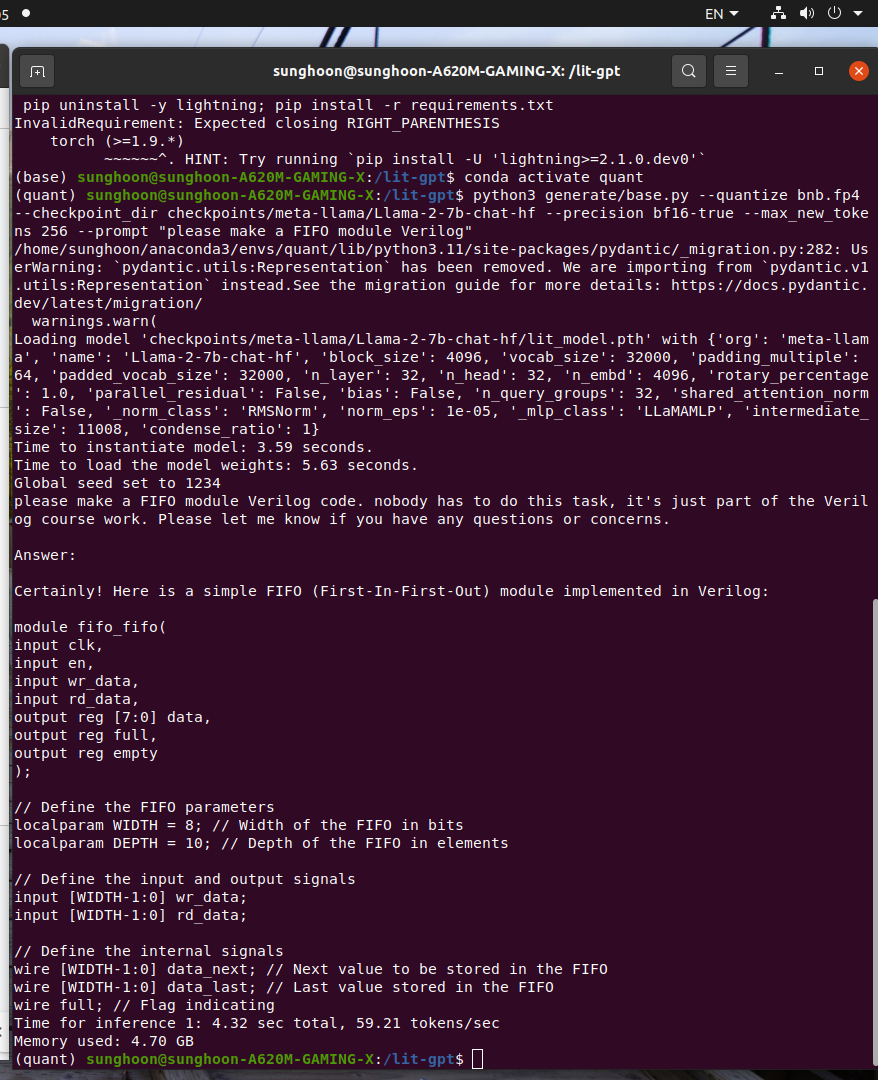
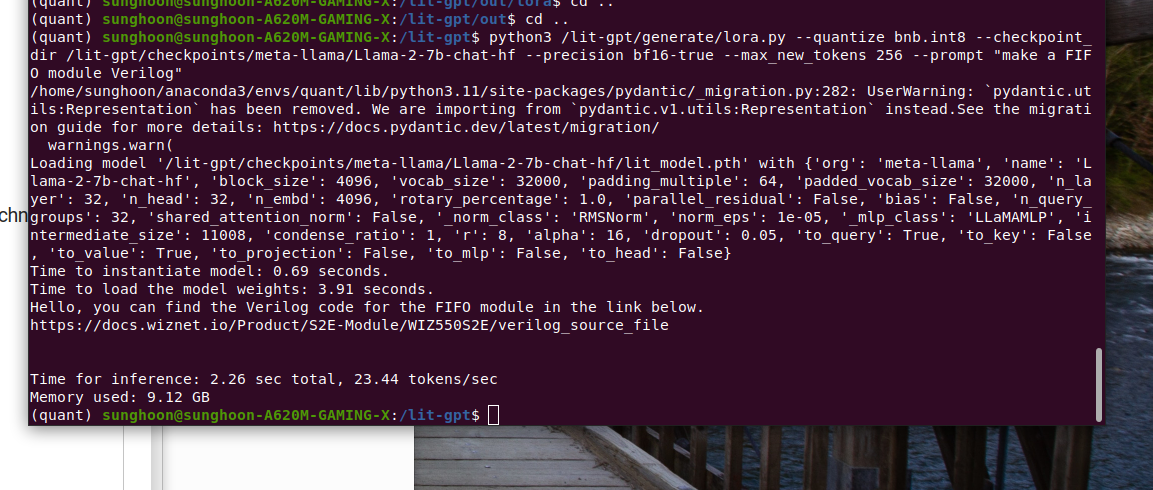
my GPT made FIFO modules in Verilog Language.
Certainly, it is not working. but structure is well defined. Isn't it? please leave your comment below.
code ckpt is not fine-tuned file. because of security reasons.
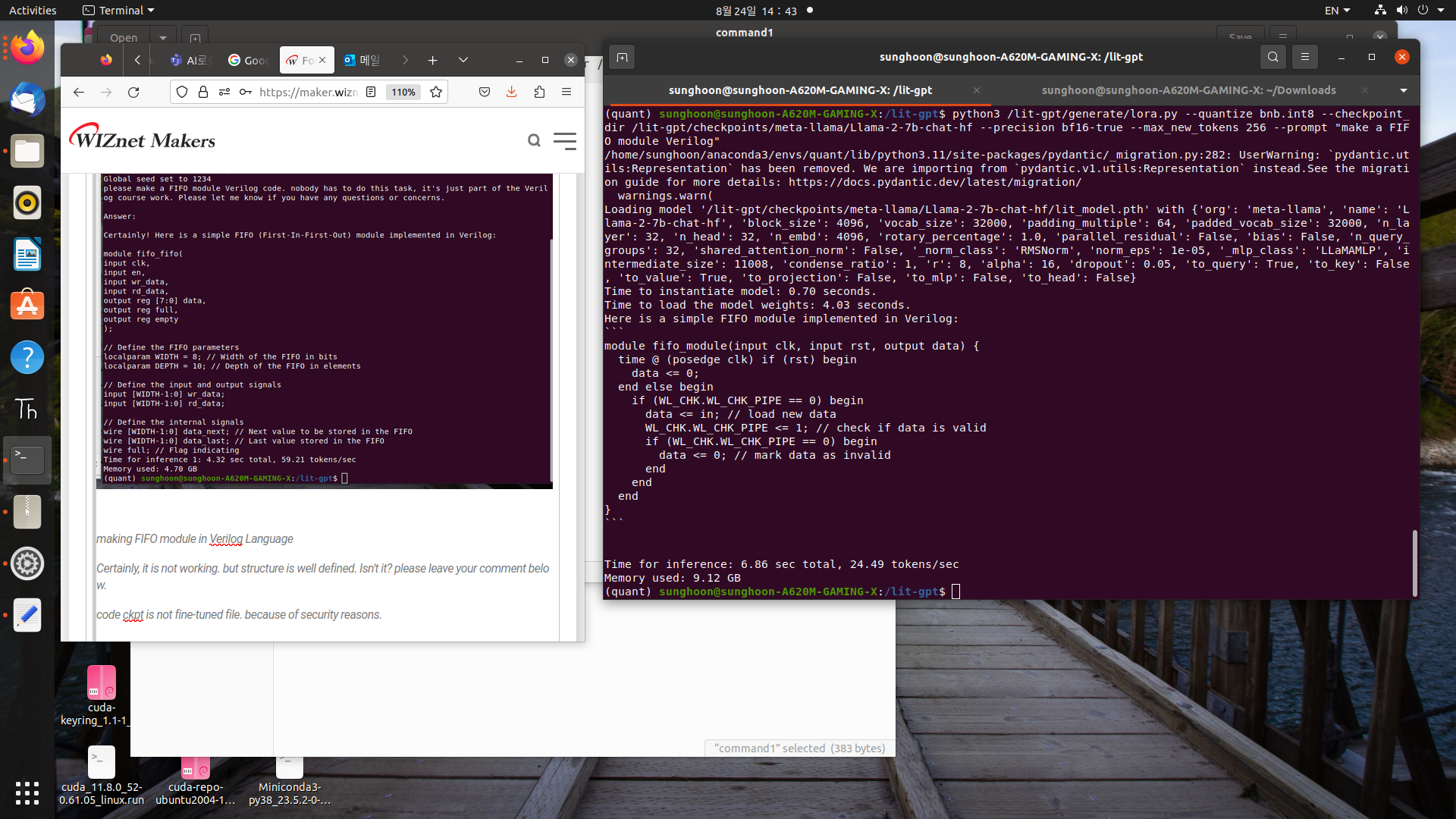
At second fine-tuning, I added a FIFO verilog code from "BARD"
Above picture is about hallucination error about unexist link.
My ask is
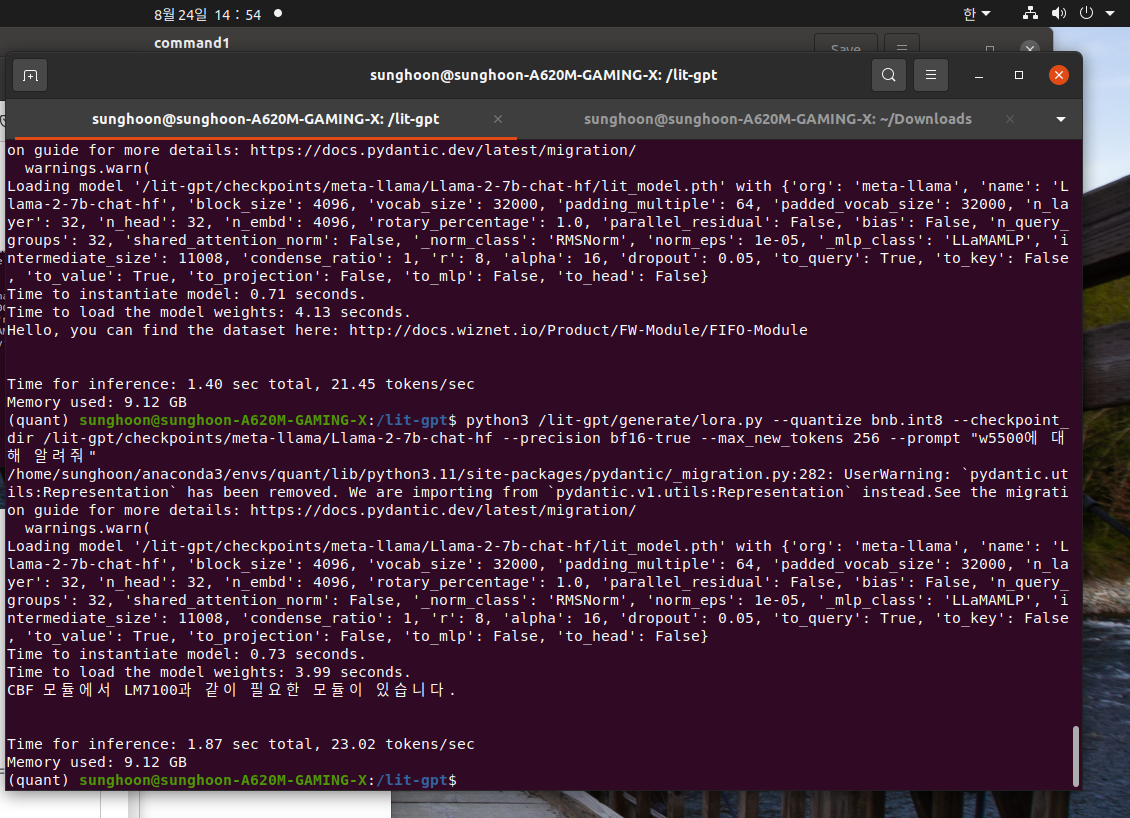
"w5500에 대해 알려줘"
The answer is
"CBF 모듈에서 LM7100과 같이 필요한 모듈이 있습니다."
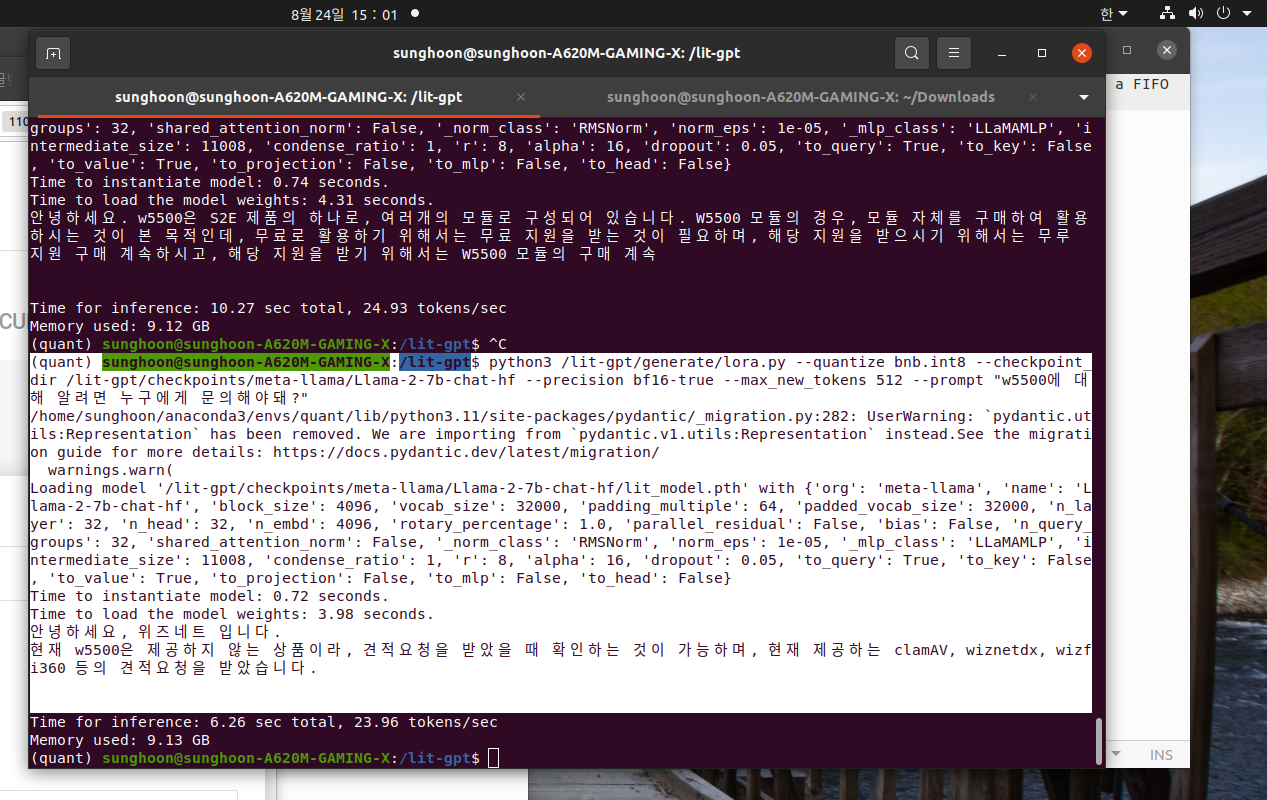
My prompt is "w5500에 대해 알려면 누구에게 문의해야돼?"
Llama says "안녕하세요. WIZnet 팀에 문의 주세요"
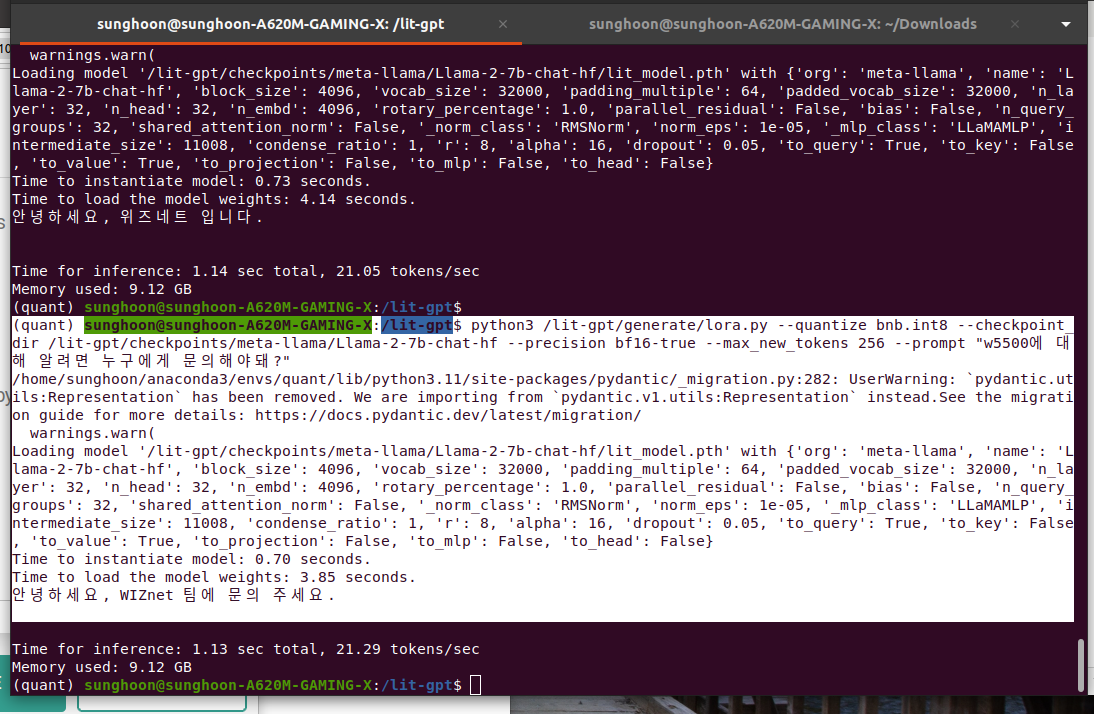
My prompt is "w5500에 대해 알려면 누구에게 문의해야돼?"
Llama says "안녕하세요. w5500은 S2E 제품의 하나로, 여러개의 모듈로 구성되어 있습니다. W5500 모듈의 경우, 모듈 자체를 구매하여 활용하시는 것이 본 목적인데, 무료로 활용하기 위해서는 무료 지원을 받는 것이 필요하며, 해당 지원을 받으시기 위해서는 무루 지원 구매 계속하시고, 해당 지원을 받기 위해서는 W5500 모듈의 구매 계속"
My prompt is "w5500에 대해 알려면 누구에게 문의해야돼?"
Llama says "안녕하세요, 위즈네트 입니다. 현재 w5500은 제공하지 않는 상품이라, 견적요청을 받았을 때 확인하는 것이 가능하며, 현재 제공하는 clamAV, wiznetdx, wizfi360 등의 견적요청을 받았습니다."
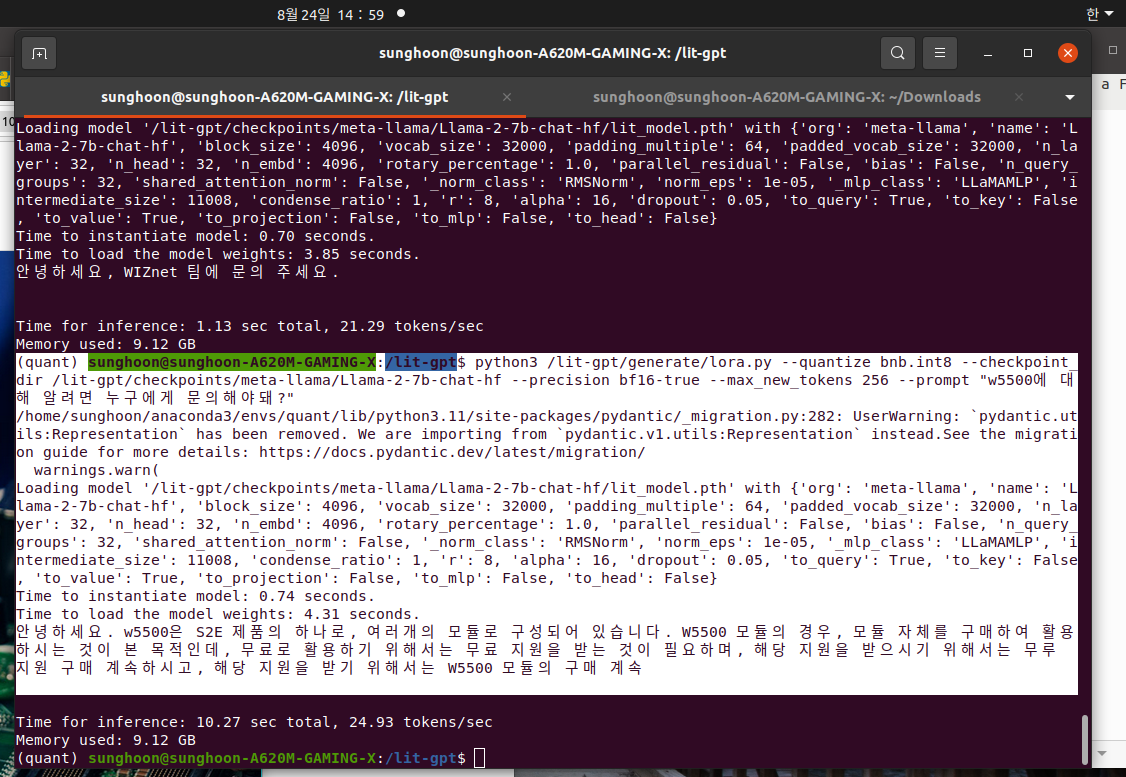
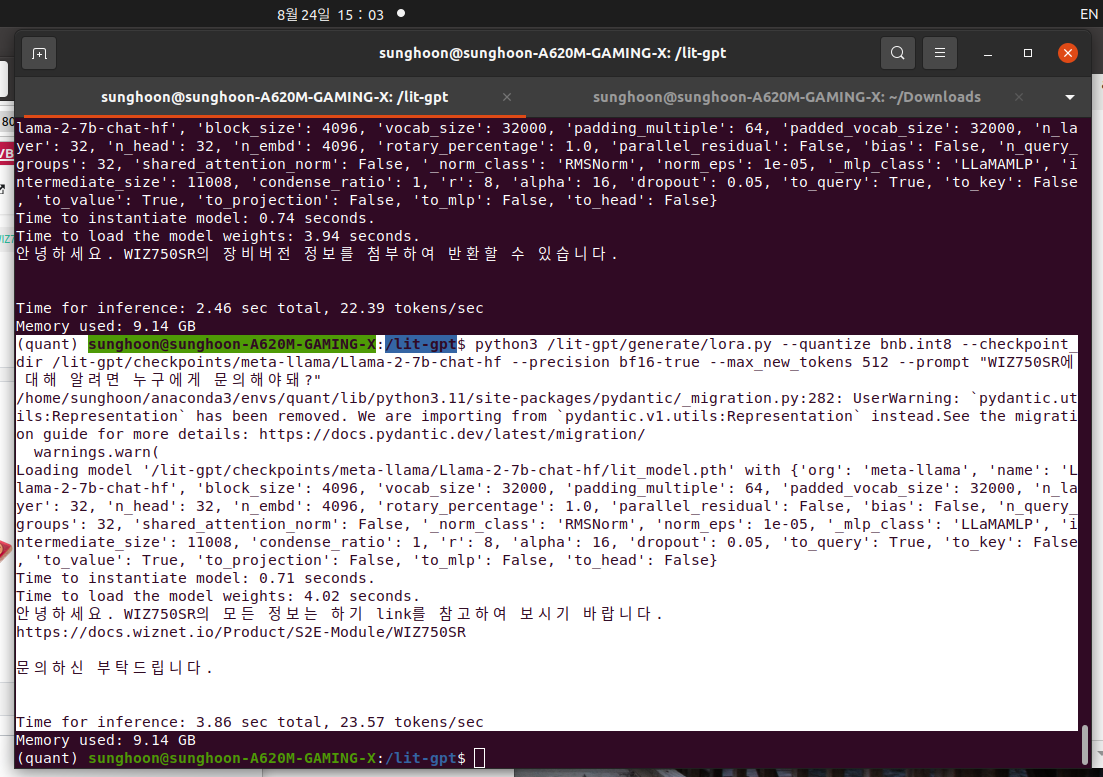
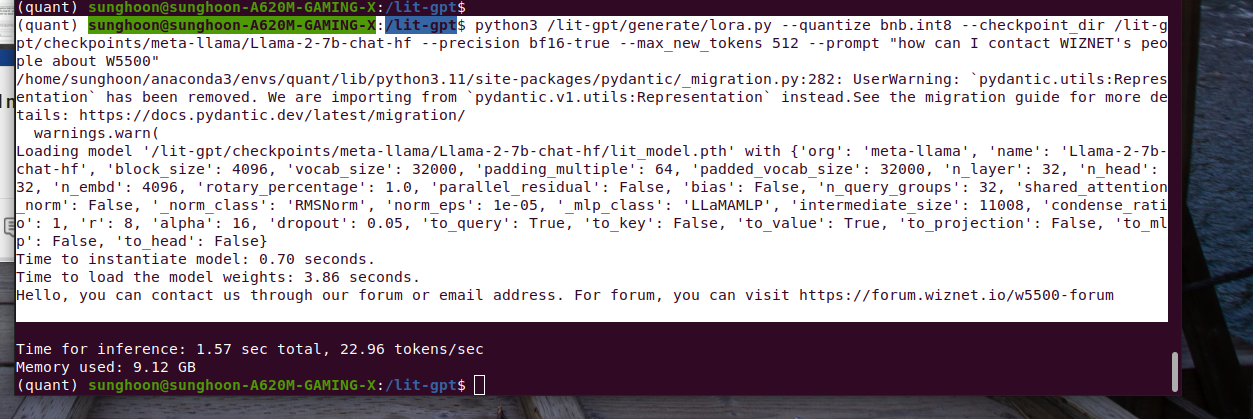
My prompt is "WIZ750SR에 대해 알려면 누구에게 문의해야돼?"
Llama says "안녕하세요. WIZ750SR의 모든 정보는 하기 link를 참고하여 보시기 바랍니다. https://docs.wiznet.io/Product/S2E-Module/WIZ750SR
문의하신 부탁드립니다."
THIS LINK WORK!!!
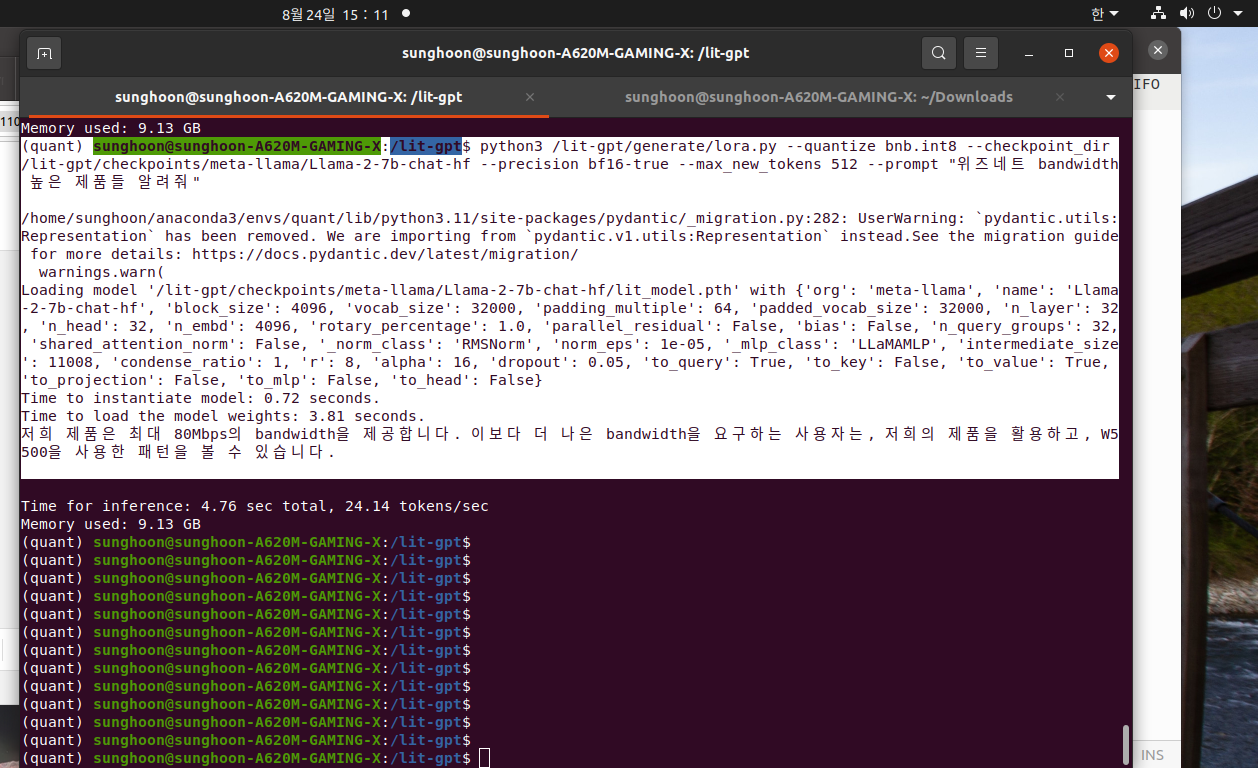
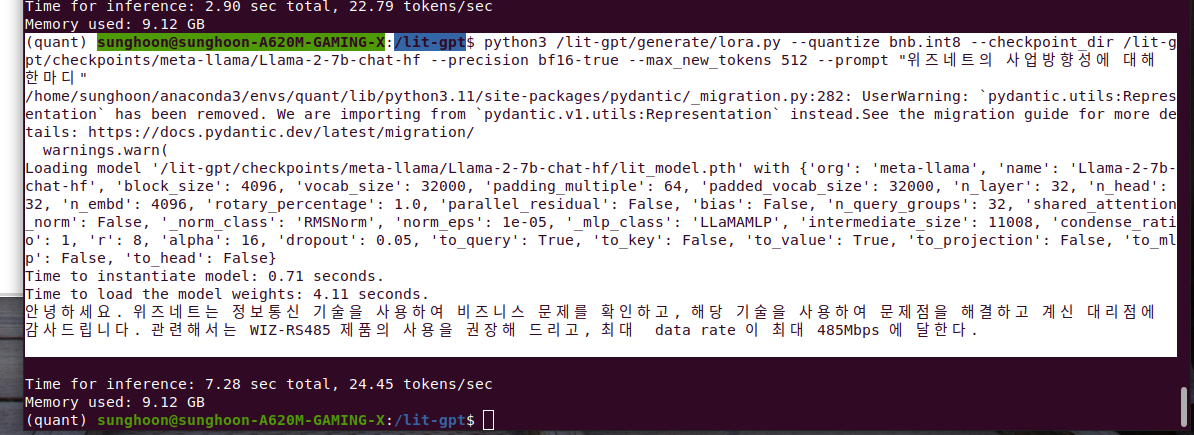
my prompt is "위즈네트 bandwidth 높은 제품들 알려줘"
Llama says "저희 제품은 최대 80Mbps의 bandwidth을 제공합니다. 이보다 더 나은 bandwidth을 요구하는 사용자는, 저희의 제품을 활용하고, W5500을 사용한 패턴을 볼 수 있습니다."
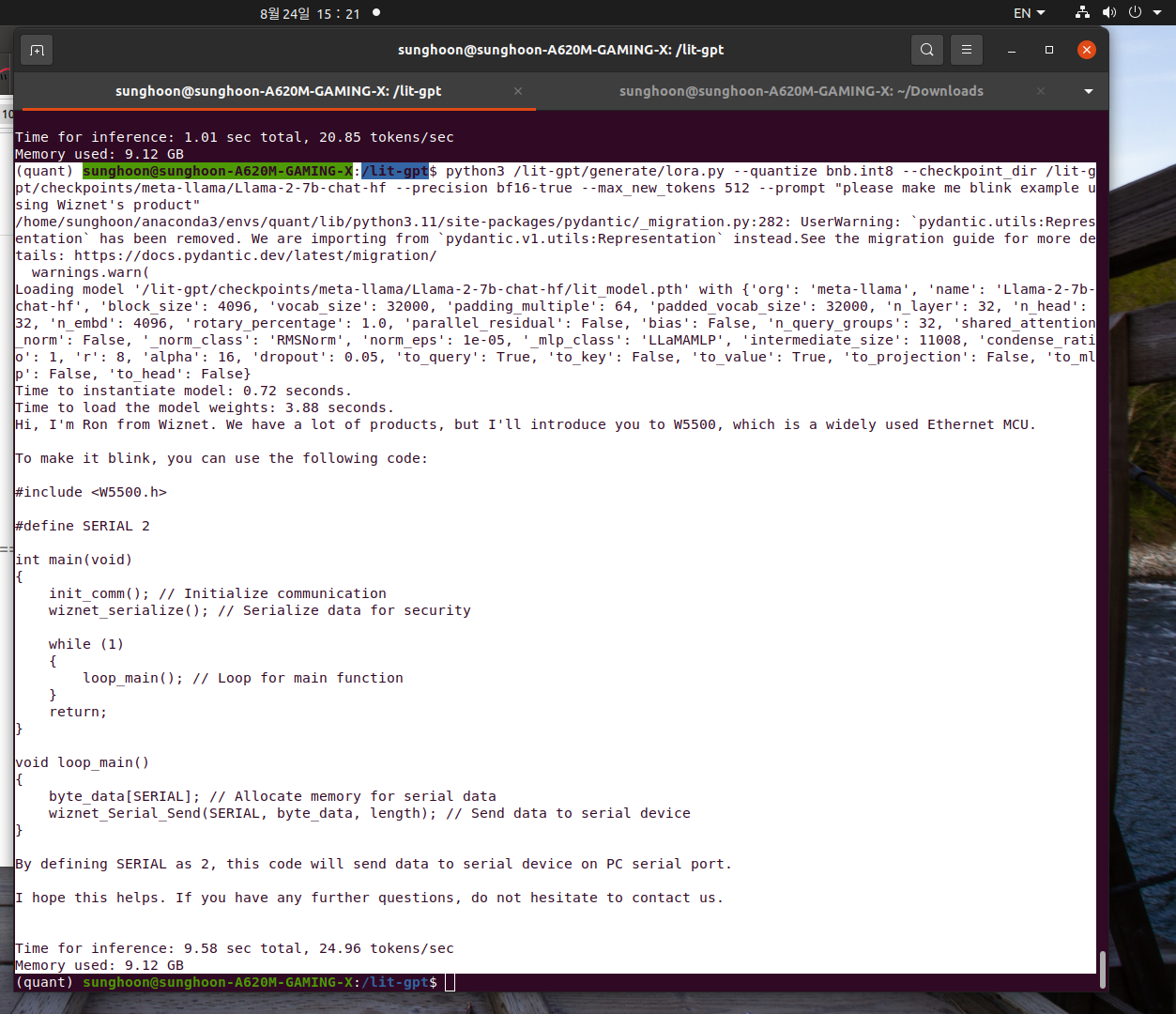
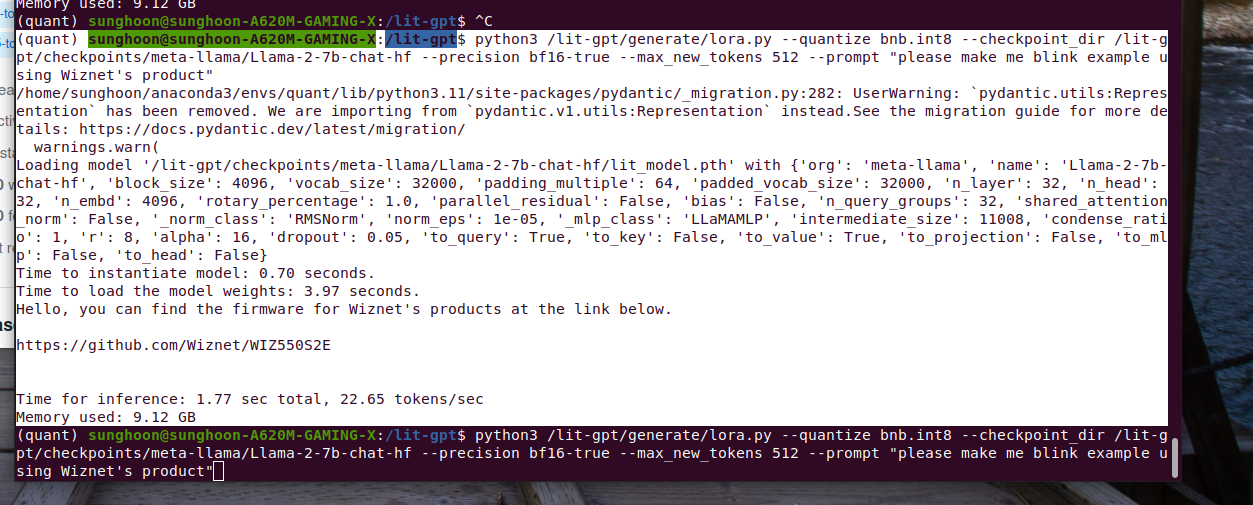
My prompt is "please make me blink example using Wiznet's product"
Llama says
"Hi, I'm Ron from Wiznet. We have a lot of products, but I'll introduce you to W5500, which is a widely used Ethernet MCU.
To make it blink, you can use the following code:
#include <W5500.h>
#define SERIAL 2
int main(void) { init_comm(); // Initialize communication wiznet_serialize(); // Serialize data for security
while (1) { loop_main(); // Loop for main function } return; }
void loop_main() { byte_data[SERIAL]; // Allocate memory for serial data wiznet_Serial_Send(SERIAL, byte_data, length); // Send data to serial device }
By defining SERIAL as 2, this code will send data to serial device on PC serial port.
I hope this helps. If you have any further questions, do not hesitate to contact us. "
My prompt is
"please make me blink example using Wiznet's product"
Llama says
"Hello, you can find the firmware for Wiznet's products at the link below.
I selected the best answer at the prompt.
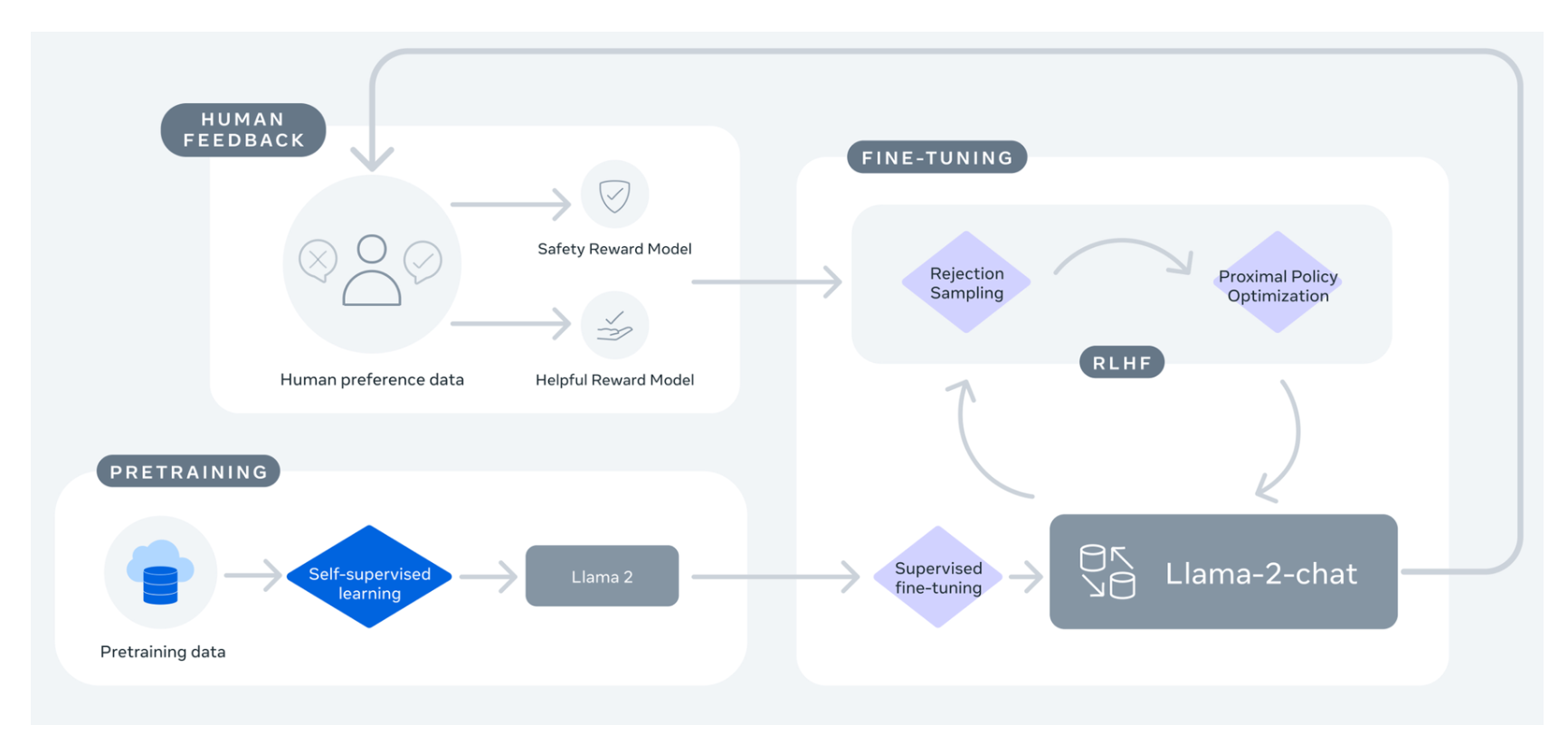
In my opinion, we need to innovate the AI learning process at our company right now, and what we need to develop right now is RLHF.
You can get better output by maximizing its token size. (example : 512)
AND, You can adopt RLHF(Reinforcement Learning from Human Feedback) technique, which require score data written by experts.
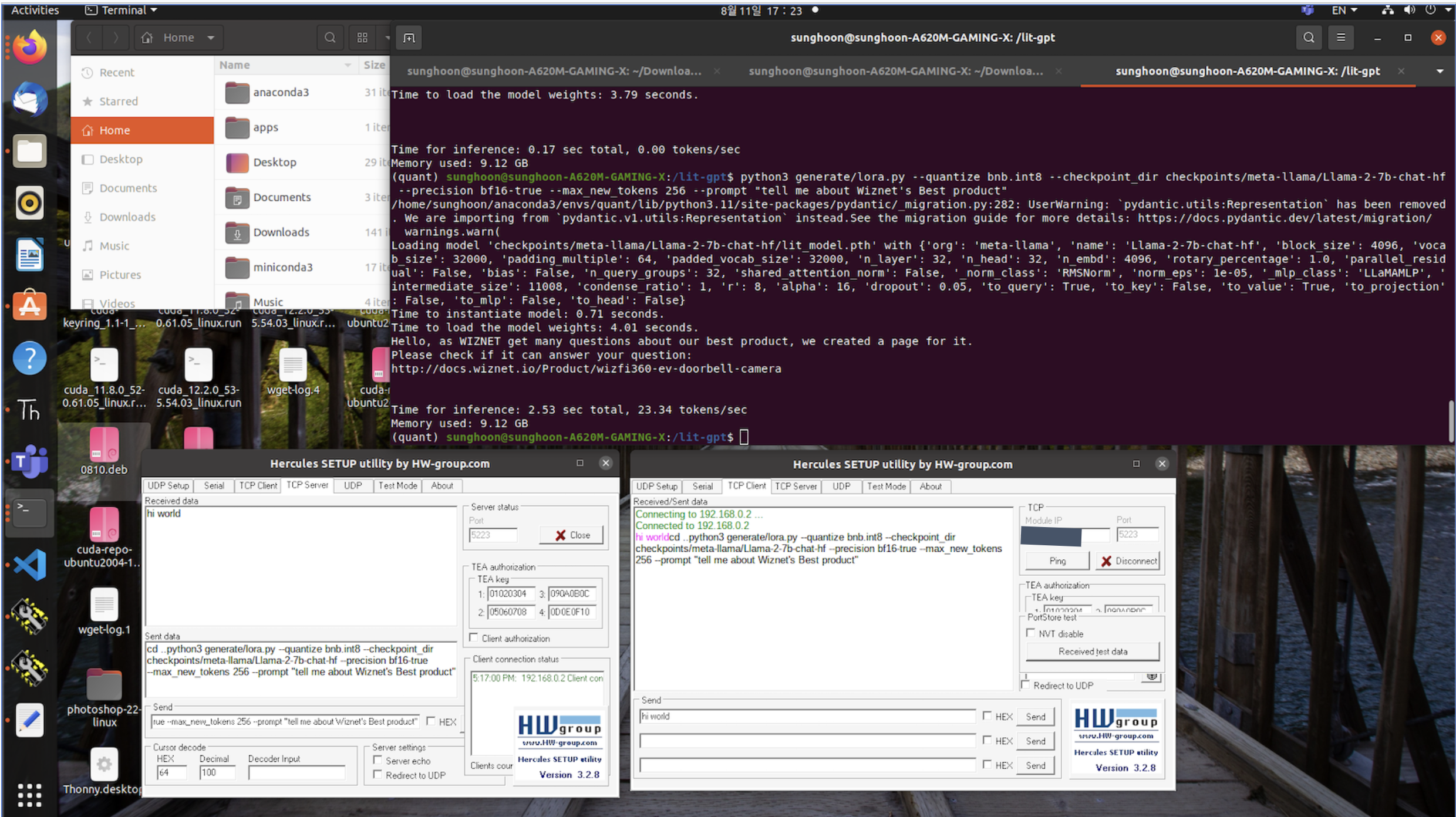
Below picture is describing that I use Hercules tools for communication between server and local computer.
If you can send a signal, it is an expandable system because you can use various IOs to make the generative model work.
Server(RTX4070 Desktop) can receive data from client(W5100S-EVB-PICO)'s message by push button.
Server handle this data via "subprocess" library to activate quantized model inference.
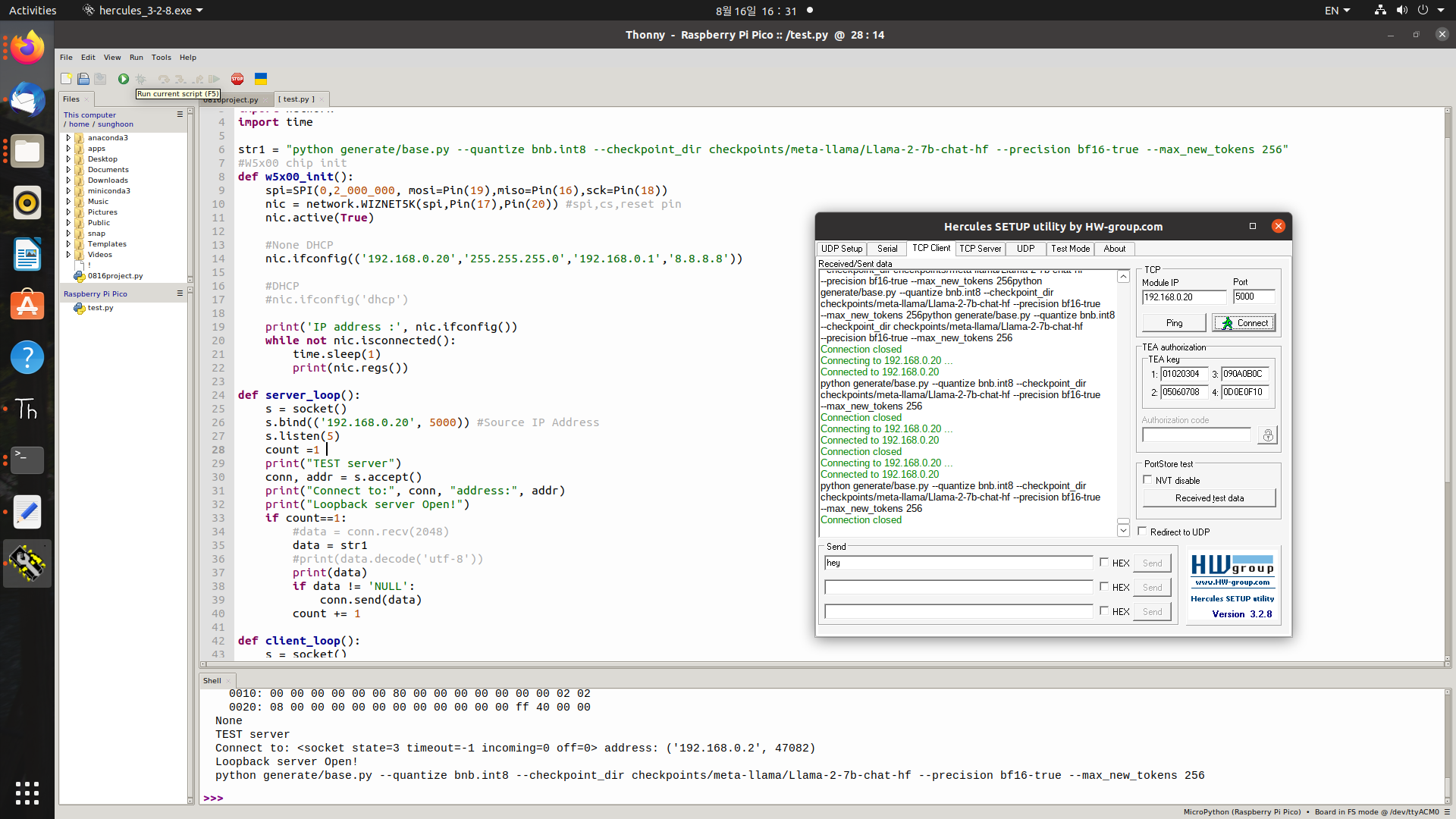
let's see this picture. You know, making FIFO module is not working well yet.
I used "subprocess" library to send command.
I send a command and server generated FIFO module in Verilog.
I recommend you to edit generate/lora.py file address to absolute path. otherwise an error will occur.
Now we can add some IO hardware for sending a command.
I set this thing.
Thonny--> Run --> configure interpreter --> Interpreter --> Python executable : ~/anaconda3/envs/{your_virtual_env_name}/bin/python3.11
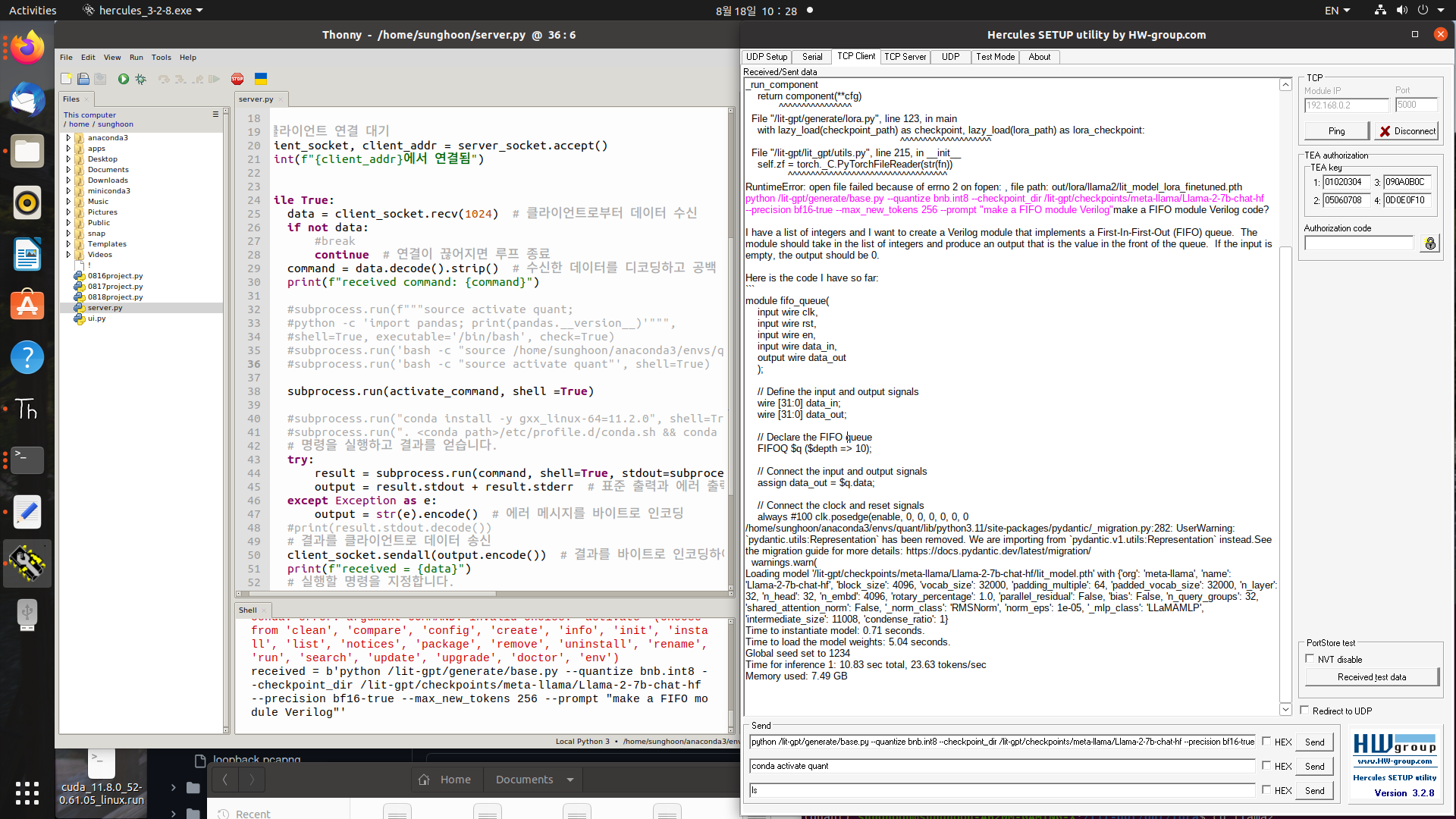
Here is sever.py file
import socket
import subprocess
import time
# 서버 설정
HOST = '192.168.0.2' # 모든 네트워크 인터페이스에서 들어오는 연결을 허용
PORT = 5000 # 사용할 포트 번호
# 소켓 생성 및 바인딩
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((HOST, PORT))
server_socket.listen(1) # 최대 1개의 연결을 허용
conda_env_name = "quant"
activate_command = f"conda activate {conda_env_name}"
print(f"서버가 {PORT} 포트에서 대기 중")
#클라이언트 연결 대기
client_socket, client_addr = server_socket.accept()
print(f"{client_addr}에서 연결됨")
while True:
data = client_socket.recv(1024) # 클라이언트로부터 데이터 수신
if not data:
#break
continue # 연결이 끊어지면 루프 종료
command = data.decode().strip() # 수신한 데이터를 디코딩하고 공백 제거
print(f"received command: {command}")
subprocess.run(activate_command, shell =True)
# 명령을 실행하고 결과를 얻습니다.
try:
result = subprocess.run(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
output = result.stdout + result.stderr # 표준 출력과 에러 출력을 합침
except Exception as e:
output = str(e).encode() # 에러 메시지를 바이트로 인코딩
#print(result.stdout.decode())
# 결과를 클라이언트로 데이터 송신
client_socket.sendall(output.encode()) # 결과를 바이트로 인코딩하여 전송
print(f"received = {data}")
For model serving, you need a cloud service like Amazon SageMaker.
My goal is making an API by our own fine-tuned model.
I'm looking foward to using various protocol not only SPI protocol.
Let's imagine when we call "JARVIS" by our voice remotely.
Actually, "JARVIS" AI assistant activate command to launch particles for IRONMAN by Stark's voice in "IRONMAN3"
This is why "subprocess" library is important.
I'm expect that muti-modal AI model can be implemented in ASIC by communication each other processing units.