
Digital-Twin + Genetic Optimization for City-Scale Solid-Waste Resource Scheduling
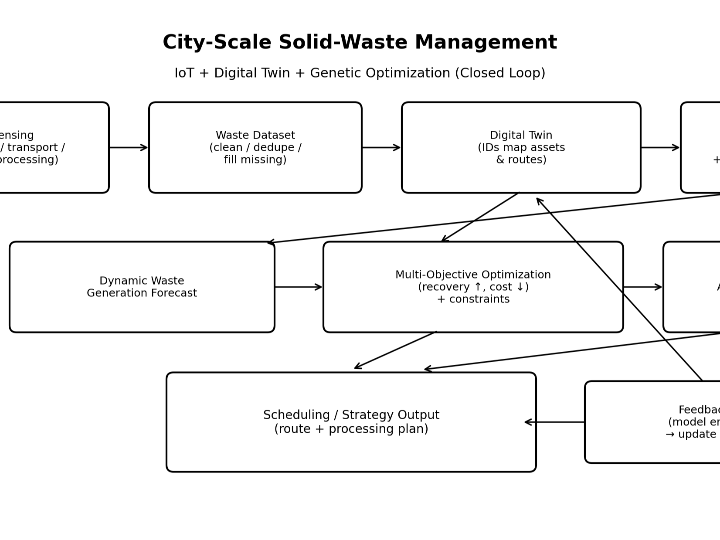
IoT data feeds a waste-system digital twin; GA optimizes routing and processing to maximize recovery while minimizing cost, with feedback updates.
Overview
This method targets a common failure of “smart” waste systems: they monitor a lot but optimize poorly when conditions change. It builds a closed loop where real-world sensing populates a dataset, a digital twin forecasts equipment capability and waste generation, and a genetic algorithm searches for strategies that balance recycling efficiency and total cost under constraints.
Main Content
1) Data acquisition and dataset formation
IoT sensors are deployed across collection, transport, sorting, and processing links to collect basic parameters and form a solid-waste dataset (with basic preprocessing like deduplication and filling missing values).
2) Digital twin modeling with system identity mapping
A virtual model mirrors the physical waste-treatment system by identifying collection points, transport routes, and processing equipment, then assigning unique IDs that bind physical entities to their digital counterparts.
3) Equipment capability prediction with risk bounds
From the twin, the method extracts operational signals such as collection frequency, processing frequency, and transport-line flow trends to estimate processing capacity under “healthy” conditions. It then performs risk assessment to output a confidence/trust interval for the capacity estimate.
4) Dynamic waste generation prediction
Using the capability prediction interval and historical waste generation, it constructs a mapping between expected waste generation and available capacity to estimate current/future waste amounts.
5) Dual-objective optimization and genetic search
It defines two optimization goals:
- Resource utilization efficiency (recycling ratio relative to total input)
- Total treatment cost (equipment operating + transport + energy consumption)
A dual-objective function is formed with constraints such as equipment capacity, transport time, classification/recovery ratios, emissions, and energy consumption. A genetic algorithm encodes strategies as individuals (e.g., matrix-coded), evolves populations, and outputs an “optimal” resource-treatment strategy.
6) Closed-loop model update
After applying the chosen strategy, the method computes the digital twin’s output error and updates the twin, enabling iterative improvement rather than one-shot planning.
System Context
This approach sits above physical waste operations as a decision-support and scheduling layer: it does not replace sorting lines, trucks, or treatment plants, but attempts to coordinate them using predictions and optimization under uncertainty.
Architecture / Design Considerations
- Core difference vs typical approaches: it couples (a) equipment capability prediction with uncertainty bounds and (b) continuous closed-loop twin updates, instead of static monitoring and fixed-parameter optimization.
- Highest failure-cost segment: incorrect capability prediction (or its uncertainty bounds) can push infeasible schedules into the optimizer, creating downstream overload, delays, or cost blowups.
- Why the digital twin matters: IDs and mirrored entities allow optimization outputs to map back to specific routes/equipment, enabling actionable scheduling instead of abstract recommendations.
- If a component is removed:
- Without IoT sensing: the system degrades into historical-only planning with slower reaction.
- Without the digital twin: optimization loses a grounded state model and becomes more static.
- Without genetic optimization: the strategy search likely collapses to heuristic/rule-based selection, reducing adaptability to complex constraints. (Interpretation based on described roles.)
Possible Implications
- Better alignment between real-time conditions and scheduling decisions can reduce equipment load swings and operating cost while maintaining recovery targets.
- The system’s value increases with heterogeneous infrastructure (many routes/equipment types), but so does sensitivity to sensor/data quality.
Conclusion
CN119273110A describes a closed-loop waste management method that combines IoT sensing, a capacity-aware digital twin (with risk bounds), and genetic multi-objective optimization to produce actionable scheduling strategies under constraints.
전체 개요
본 특허는 “스마트 도시” 폐기물 관리에서 흔히 발생하는 문제, 즉 모니터링은 되는데 최적화는 정교하지 못한 상태를 겨냥합니다. 이를 위해 IoT 데이터 수집 → 디지털 트윈 구성 → 처리 설비 능력(용량) 예측 + 리스크(신뢰구간) 산출 → 발생량 동적 예측 → (효율/비용) 2목표 최적화 → 유전알고리즘으로 전략 탐색 → 디지털 트윈 오차 기반 갱신의 폐루프를 구성합니다.
문제의식과 기술적 맥락 재구성
- 기존 접근은 설비 상태를 “정적으로” 보거나 통계 수준에서 다루는 경우가 많아, 설비 잠재 용량을 제대로 못 쓰거나 예측 오차로 시스템 불안정이 커질 수 있다고 봅니다.
- 다목적 최적화가 있더라도 파라미터가 고정되어 있으면, 폐기물 발생량/조건 변동에 따라 효율이 급락할 수 있습니다.
- 또한 피드백이 느리면 “한 번 계산한 계획”이 계속 굴러가며, 실시간 폐루프 최적화가 어렵다는 문제의식이 깔려 있습니다.
기술 흐름 설명 (신호 / 데이터 / 동작 순서 중심)
- 센서 수집(입력 신호 확보)
수거, 운송, 분류, 처리 단계에 IoT 센서를 배치해 기본 파라미터를 수집하고 데이터셋을 만듭니다. - 데이터 정리(최소한의 품질 확보)
중복 제거, 결측치 처리(평균값 채움) 같은 전처리를 수행합니다. - 디지털 트윈 구성(물리-가상 매핑)
수거 지점, 운송 라인, 처리 설비를 식별하고 유일 ID를 부여하여 가상 모델에 연결합니다. - 설비 처리능 예측 + 리스크 평가(불확실성 포함)
수집/처리 빈도, 운송 라인 유량 추세 등을 기반으로 처리능을 추정하고, 신뢰구간을 산출합니다. - 발생량 동적 예측(설비능-발생량 관계)
처리능 신뢰구간 + 과거 발생량으로 매핑 관계를 만들어 현재/미래 발생량을 추정합니다. - 2목표 최적화 + 유전알고리즘 탐색(전략 산출)
목표는 (a) 자원화 효율, (b) 처리비용(운영+운송+에너지)이며, 제약은 설비능/시간/분류 비율/배출/에너지 등으로 구성합니다. 이후 유전알고리즘이 후보 전략(개체)을 진화시켜 최적 전략을 선택합니다. - 오차 계산으로 트윈 갱신(폐루프 완성)
선택 전략으로부터 트윈 출력 오차를 계산해 모델을 업데이트합니다.
왜 이런 구조가 나왔는지에 대한 해설
- 핵심은 “예측(상태)과 최적화(의사결정)를 분리”하되, 둘을 폐루프로 묶는 것입니다. 예측이 정지된 상태면 최적화가 금방 낡고, 최적화가 정지된 상태면 데이터는 쌓이기만 합니다.
- 특히 본 특허는 처리 설비 능력에 대해 **신뢰구간(불확실성)**을 명시적으로 만들고, 이를 바탕으로 전략을 고르는 쪽으로 설계를 끌고 갑니다.
설계 선택의 배경, 제약 조건, 대안 가능성
- **2목표(효율 vs 비용)**로 잡은 이유는, 현실 운영이 “최대한 자원화”만 추구하면 비용과 병목이 터지고, “최저 비용”만 추구하면 자원화율/규제(배출)가 무너지는 구조이기 때문으로 보입니다(추론임).
- 제약을 설비능/시간/비율/배출/에너지로 걸어 둔 것은, 실제 운영에서 바로 위반하기 쉬운 요소들이고, 위반 시 피해가 크기 때문으로 읽힙니다(추론임).
- 대안으로는 선형계획/강건최적화/룰 기반 운영 등이 있을 수 있으나, 여기서는 복합 제약과 동적 조건을 “탐색”으로 다루기 위해 유전알고리즘을 채택한 형태입니다(추론임).
생소한 개념에 대한 풀어쓴 설명
- 디지털 트윈: 실제 시스템(수거지, 노선, 설비)을 가상 모델에 대응시켜, “가상에서 먼저 운영 시나리오를 돌려보는” 구조입니다. 여기서는 ID를 부여해 실체와 모델을 묶는 점이 강조됩니다.
- 신뢰구간(Trusted/Credible interval로 표기됨): 설비 처리능 예측이 “딱 한 값”이 아니라, 오차 가능성을 포함한 범위로 주어지는 것입니다. 최적화가 이 범위를 무시하면 현장에서는 계획이 쉽게 깨집니다.
- 유전알고리즘: 가능한 운영 전략 조합을 “개체”로 보고, 평가(적합도) 후 선택/교차/변이를 통해 더 나은 전략을 찾는 탐색 방식입니다.
시스템 구성 및 선택지 해석
- 본 시스템은 설비나 차량을 직접 제어하는 장치라기보다, **운영 전략을 계산해주는 상위 레이어(보조 수단)**에 가깝습니다(추론임). 실제 처리는 기존 설비가 수행하고, 이 방법은 “어떤 경로/설비에 얼마만큼 배분할지”를 계산해 주는 성격입니다.
- 구성요소 제거 시 성격 변화(필수 앵커)
- IoT 센서가 빠지면: 실시간성이 약화되어 과거 데이터 중심의 계획으로 후퇴할 가능성이 큽니다(추론임).
- 디지털 트윈이 빠지면: 물리 시스템 상태를 반영한 예측/피드백이 약해져 “정적 최적화”에 가까워질 수 있습니다(추론임).
- 유전알고리즘이 빠지면: 복합 제약 하에서 탐색력이 줄어 규칙 기반 또는 제한된 탐색으로 성격이 바뀔 수 있습니다(추론임).
내부 관점에서의 시사점
- 이 방식의 성패는 “모델이 똑똑하냐”보다 입력 데이터 품질과 설비 처리능 예측의 신뢰구간이 현실을 얼마나 반영하느냐에 더 좌우될 가능성이 큽니다(추론임).
- 또한 2목표 최적화는 결과가 “하나의 정답”이 아니라 트레이드오프 집합이 될 수 있어, 운영 조직이 어떤 정책(비용 우선/자원화 우선)을 채택하는지에 따라 실제 적용 형태가 달라질 여지가 있습니다(추론임).
FAQ (4–7)
Q1. 기존 “스마트 폐기물” 접근 대비 핵심 차이는 무엇인가요?
기존은 센서 기반 모니터링이나 정적 최적화에 머무르는 경우가 많습니다. 본 특허는 디지털 트윈을 오차 기반으로 갱신하고, 설비 처리능을 신뢰구간으로 다룬 뒤 최적화로 넘기는 폐루프를 강조합니다.
Q2. 시스템에서 실패 비용이 가장 큰 구간은 어디인가요?
설비 처리능 예측이 틀리거나 신뢰구간이 비현실적이면, 최적화가 “가능해 보이지만 현장에서는 불가능한” 전략을 뽑을 수 있습니다. 그 결과는 병목, 지연, 비용 폭증으로 이어지기 쉬워 보입니다(추론임).
Q3. 핵심 데이터 흐름을 한 줄로 요약하면 어떻게 되나요?
IoT 센서 데이터로 데이터셋을 만들고, 디지털 트윈에서 설비능과 발생량을 예측한 다음, 효율/비용 2목표 최적화를 유전알고리즘으로 풀어 전략을 만들고, 그 결과 오차로 트윈을 갱신합니다.
Q4. 왜 이 설계는 “보조 수단”에 가까운가요?
문서가 설명하는 산출물은 “처리 전략/스케줄링 결정”이며, 실제 처리 행위(분류기 가동, 차량 운행, 설비 물리 처리)는 기존 인프라가 수행합니다. 즉, 본 방법은 운영 의사결정을 계산해주는 상위 레이어로 해석하는 것이 자연스럽습니다(추론임).
Q5. 디지털 트윈에서 ID를 부여하는 부분은 왜 중요하나요?
최적화 결과가 “어느 설비/어느 노선/어느 수거지”에 대응되는지 매핑이 되지 않으면, 전략은 현장 적용이 어렵습니다. ID는 물리 요소와 가상 모델을 결속시키는 최소 단위로 보입니다(추론임).
저자 정보 (Author Information)
汪海涛
周铮
季倩玉
소속/기관의 성격 설명: 공개 페이지에는 기업(지능형 기술/솔루션 제공 성격으로 추정됨) 명의의 출원 정보가 보이지만, 상세한 연구·공학적 배경은 공개된 범위가 제한적입니다(정보 제한 / 추론임).