
How to build the WIZnet AI Chatbot with Azure, OpenAI and ChromaDB
This is an example of implementing a RAG chatbot by reading a pdf.
microsoft - Microsoft Azure
x 1
OpenAI - ChatGPT
x 1
Python - Python
x 1
Overview
Continuing from my previous introduction to corporate LLM model development strategies, I have now practically implemented a Retrieval-Augmented Generation (RAG) based search method. This approach is especially beneficial in corporate environments for creating document-based Q&A systems and holds great potential for broader applications in the future.
What's RAG?
Retrieval Augmented Generation (RAG) is a technique used in natural language processing (NLP) to generate customized output that is outside the scope of the existing training data. For example, asking ChatGPT to summarize an email without RAG is similar to asking it to do so without providing the context of the actual email.
The RAG system consists of two main components: A retriever and a generator.
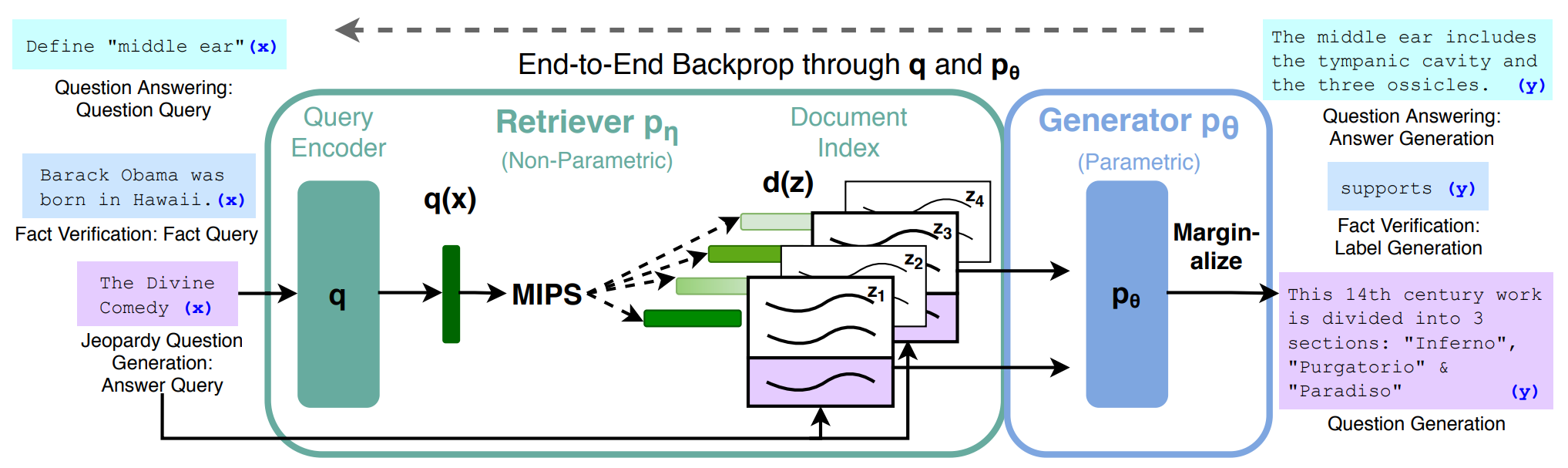
The retriever is responsible for finding the most relevant information in the knowledge base that is relevant to a given input. Based on these search results, the generator builds a set of prompts based on predefined prompt templates to generate a consistent and relevant response to the input.
In a typical RAG architecture, the knowledge base consists of vector embeddings stored in a vector database (e.g., ChromaDB). A searcher takes a given input in real-time and searches the vector space containing the data to find the top K most relevant search results, which are then passed to a generator such as an LLM (e.g. GPT-4, lLama2, etc.) to produce a set of prompts based on them.
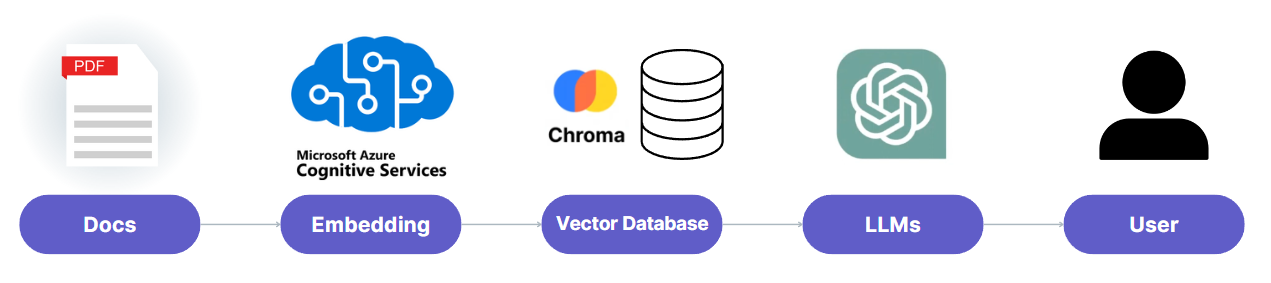
Introduction to RAG, Vector Databases, and OCR
- Azure OCR : We utilize OCR from Azure Cognitive Services to extract texts and tables from PDF documents.
- Vector Database (ChromaDB): The extracted texts are vectorized and stored in ChromaDB, which is used to search for texts relevant to user queries.
- RAG Process: User queries are vectorized, and the most similar text snippets from the vector database are fetched to enable ChatGPT to generate responses based on them.
Project Setup and Implementation
- Installation of necessary tools: We install packages like OpenAI API, ChromaDB, Azure AI Form Recognizer, Streamlit, and Tabulate.
pip install streamlit azure-ai-formrecognizer openai chromadb tabulate- Building the Chatbot UI with Streamlit: We set up an interface for users to upload PDF files and ask questions.
Extracting and Vectorizing Text from PDF
- Texts are extracted from PDF using Azure AI document intelligence and then vectorized for storage in ChromaDB. This process is effective even with complex PDF structures.

# Create a temporary file to write the bytes to
with open("temp_pdf_file.pdf", "wb") as temp_file:
temp_file.write(uploaded_file.read())
AZURE_COGNITIVE_ENDPOINT = "own_key"
AZURE_API_KEY = "own_key"
credential = AzureKeyCredential(AZURE_API_KEY)
AZURE_DOCUMENT_ANALYSIS_CLIENT = DocumentAnalysisClient(AZURE_COGNITIVE_ENDPOINT, credential)
# Open the temporary file in binary read mode and pass it to Azure
with open("temp_pdf_file.pdf", "rb") as f:
poller = AZURE_DOCUMENT_ANALYSIS_CLIENT.begin_analyze_document("prebuilt-document", document=f)
doc_info = poller.result().to_dict()Generating Chatbot Responses
- The chatbot queries ChromaDB based on user input to fetch related data.
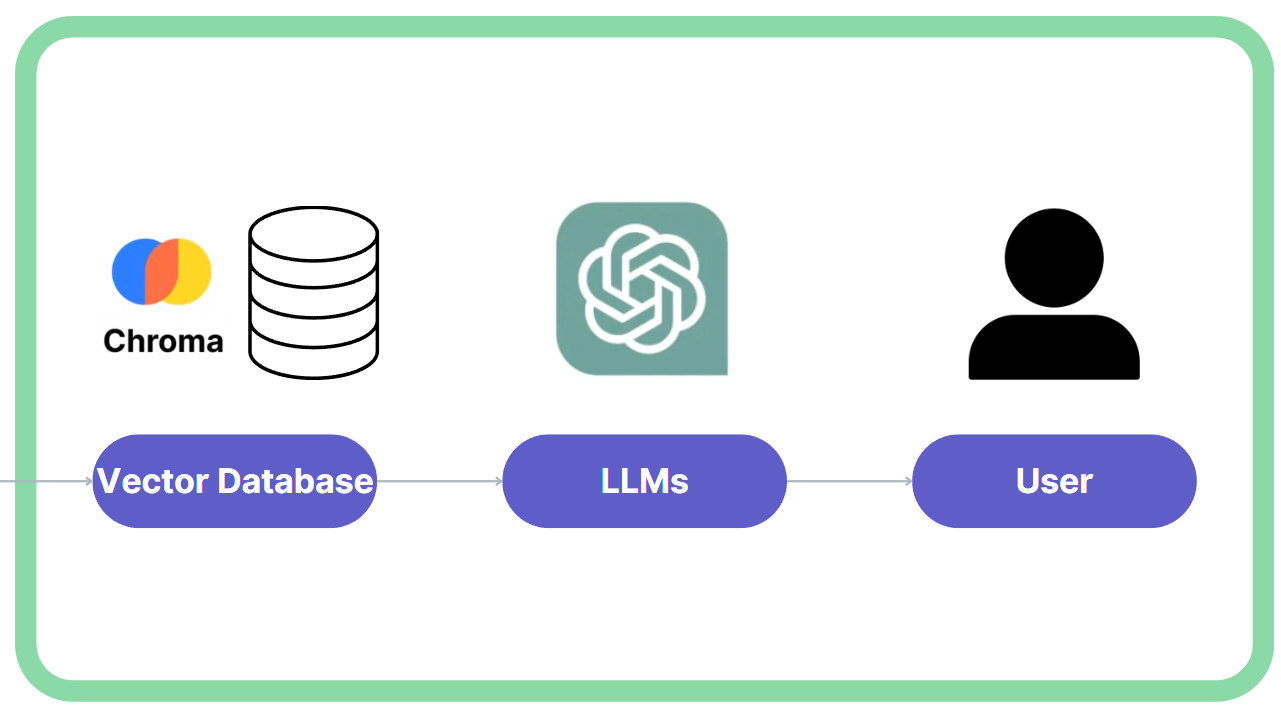
- OpenAI's GPT-4 model is used to generate appropriate responses based on the retrieved data.
# query ChromaDB based on your prompt, taking the top 5 most relevant result. These results are ordered by similarity.
q = collection.query(
query_texts=[prompt],
n_results=3,
)
results = q["documents"][0]
prompts = []
for r in results:
# construct prompts based on the retrieved text chunks in results
prompt = "Please extract the following: " + prompt + " solely based on the text below. Use an unbiased and journalistic tone. If you're unsure of the answer, say you cannot find the answer. \n\n" + r
prompts.append(prompt)
prompts.reverse()
openai_res = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "assistant", "content": prompt} for prompt in prompts],
temperature=0,
)
response = openai_res["choices"][0]["message"]["content"]
Running and Testing the Streamlit App
- The built chatbot is tested in real-time to optimize the user experience.
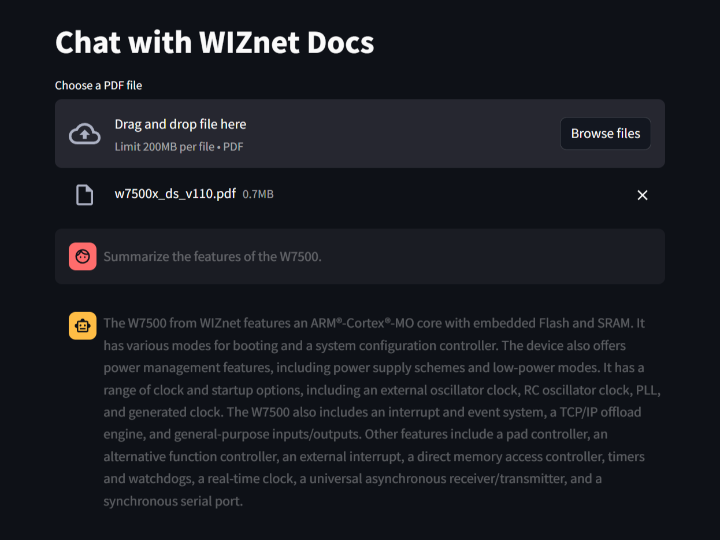
st.write("# Chat with WIZnet Docs")
uploaded_file = st.file_uploader("Choose a PDF file", type="pdf")
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("What do you want to say to your PDF?"):
# ... (User input processing and chatbot response generation code)
# append the response to chat history
st.session_state.messages.append({"role": "assistant", "content": response})
Conclusion and Outlook
Through this tutorial, we've learned how to efficiently build a PDF QA chatbot by combining Azure's OCR capabilities, ChromaDB, and the OpenAI API. This chatbot serves as a powerful tool for creating document-based Q&A systems. Moreover, this method is applicable across various industries and is expected to be adopted by more businesses and sectors in the future.
You can find the source code at the following link: wiznetmaker github
Thank you for reading.