TinyML - WakeWord Detection
Let’s do wakeword detection with W5500-evb-pico.


WIZnet - W5500-EVB-Pico
x 1
microsoft - VS Code
x 1

Arduino - Arduino IDE
x 1
Summary
This post discusses a system for speech recognition. It covers the principles of speech recognition, including the Fourier Transform and STFT (Short Time Fourier Transform). It provides code examples for collecting and preprocessing speech data using Arduino and Python, training a model, and converting it using TensorFlow Lite. The system architecture and operation are explained in detail, along with the implementation steps using Arduino and Python code.
Overview
In order to get a better understanding of the techniques underlying Wake Word Detection in resource-limited IoT devices, we shall conduct our investigation on Arduino that is far less powerful than the such as iPhone.
We will use the existing dataset, train our model with Tensorflow, convert it into the TensorFlow Lite model and deploy the model into Arduino. Then we shall Arduino IDE messages to get output information.

Prior Knowledge
Principles of voice recognition - sound
The sound source is drawn with the following waveform.
It is difficult to extract characteristic values from the sound source itself, and since the number of characteristic values increases exponentially, it is impossible to extract characteristics from sensor values alone.
Fourier transform and spectrogram
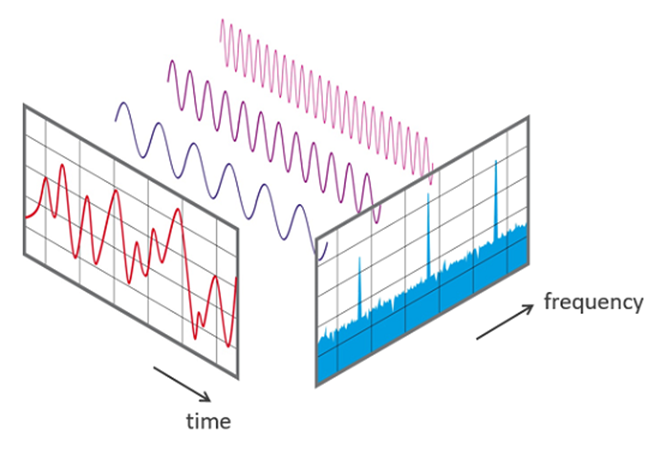
- Perform Fourier transformation on the sound source to change the waveform of the [time axis] to the waveform of the [frequency axis].
Characteristics can be extracted at which frequency the gain is large.
-However, because speech has temporal characteristics, it is difficult to classify it based on frequency characteristics alone.
-For example, if you only look at the frequency characteristics, you will not be able to distinguish between “Banana” and “naBana.”
STFT(Short Time Fourier Transform)
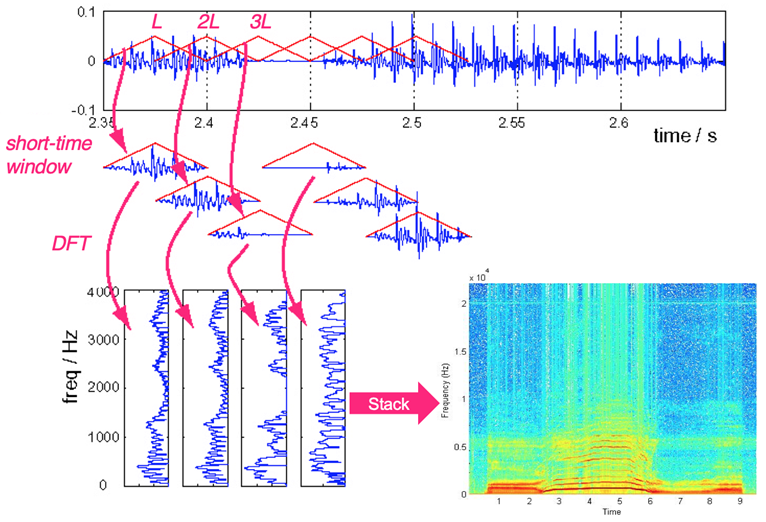
-Try Fourier transform by dividing the time of the sound source into short segments
-The accumulated form of the Fourier transformed graph by rotating it counterclockwise is called STFT.
-The size of the frequency range is expressed as a value between 0 and 255.
-In this code, we attempted Fourier transform by converting to (257X4) tensor.
System Diagram
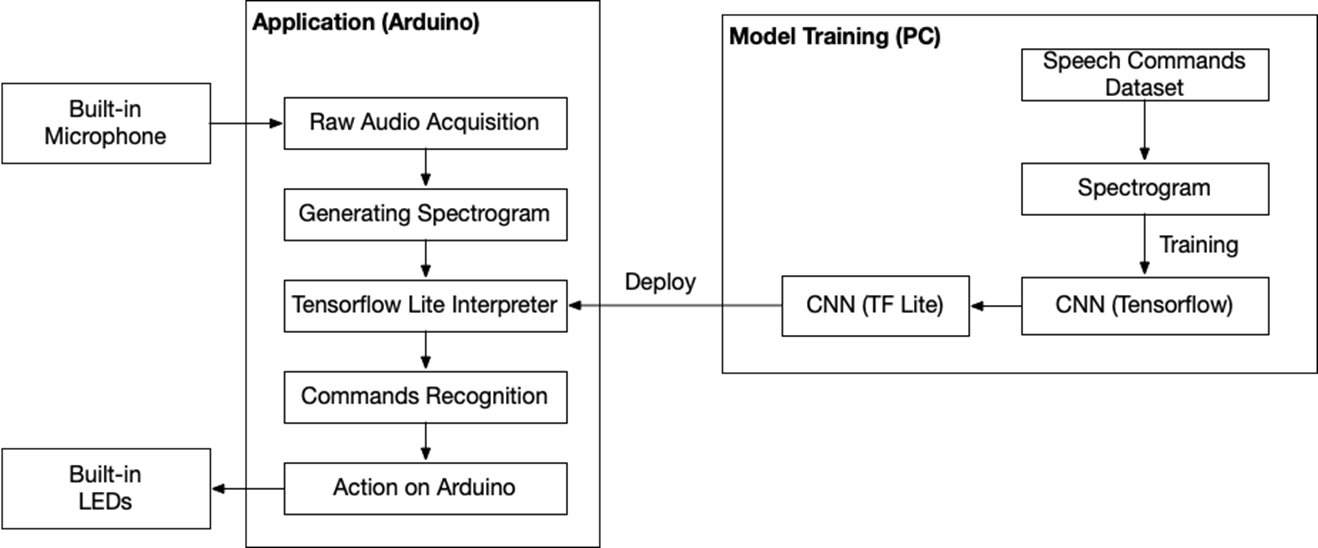
Convert the data set to a spectrogram on the PC and train it.
It learns with CNN, and the learned data is converted to TFLite and binaryized into .cpp to fit the Arduino model.
Afterwards, Arduino loads the model and injects sensor values into the model to make inferences.
Code
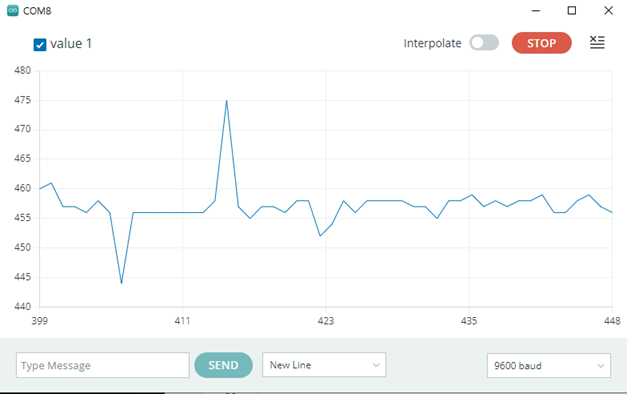
Get_sounds.ino
#include <fix_fft.h>
const int analogSensorPin = 26;
const int ledPin = LED_BUILTIN;
const int sampleRate = 1000;
const int sampleTime = 1;
const int totalSamples = sampleRate * sampleTime;
int16_t vReal[totalSamples];
int16_t vImag[totalSamples];
unsigned long startTime;
void fft_wrapper(int16_t* vReal, int16_t* vImag, int n, int inverse) {
fix_fft((char*)vReal, (char*)vImag, n, inverse);
}
void setup() {
Serial.begin(9600);
pinMode(ledPin, OUTPUT);
}
void loop() {
//Serial.print("fft calculate");
digitalWrite(ledPin, HIGH);
startTime = millis();
for (int i = 0; i < totalSamples; i++) {
vReal[i] = analogRead(analogSensorPin);
vImag[i] = 0; // 허수부는 0으로 초기화
while (millis() < startTime + (i * 1000.0 / sampleRate));
}
digitalWrite(ledPin, LOW);
// FFT 계산
fft_wrapper(vReal, vImag, 10, 0);
// FFT 결과 출력
for (int i = 0; i < totalSamples / 2; i++) {
double frequency = (i * 1.0 * sampleRate) / totalSamples;
double magnitude = sqrt(vReal[i] * vReal[i] + vImag[i] * vImag[i]);
//Serial.print(frequency);
//Serial.print(",");
Serial.println(magnitude);
}
delay(2000);
}
get_voice_data.py
import serial
import numpy as np
import librosa
import csv
# 아두이노에서 데이터 읽어오기
ser = serial.Serial('COM13', 9600)
sampleRate = 1000
sampleTime = 1
totalSamples = sampleRate * sampleTime
while True:
try:
data = []
while len(data) < totalSamples:
if ser.in_waiting:
value = ser.readline().decode().strip()
if value:
data.append(float(value))
# 데이터 전처리
data = np.array(data)
data = data / 1023.0 # 정규화
# 오디오 데이터 변환
sr = sampleRate # 샘플링 레이트
audio = librosa.resample(data, orig_sr=sr, target_sr=sr) # 리샘플링
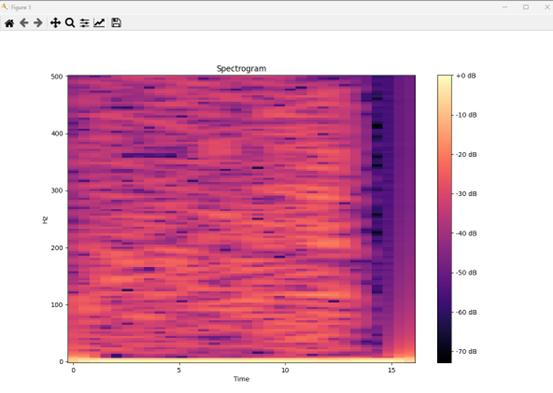
stft = librosa.stft(audio, n_fft=512, hop_length=256) # STFT 적용
spectrogram = librosa.amplitude_to_db(np.abs(stft), ref=np.max) # 스펙트로그램 변환
# 스펙트로그램 데이터를 CSV 파일로 저장
with open('you.csv', 'a', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(spectrogram)
except KeyboardInterrupt:
break
ser.close()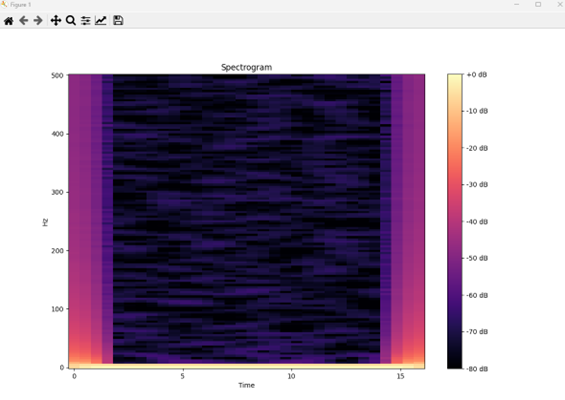
Train_voice_data.ipynb
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.model_selection import train_test_split
# CSV 파일 읽어오기
nothing_data = pd.read_csv('nothing.csv', header=None)
wiznet_data = pd.read_csv('wiznet.csv', header=None)
you_data = pd.read_csv('you.csv', header=None)
# 데이터 병합 및 레이블 할당
data = np.vstack((nothing_data, wiznet_data, you_data))
labels = np.concatenate((np.zeros(len(nothing_data)), np.ones(len(wiznet_data)), np.ones(len(you_data))*2))
# 학습 데이터와 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
# 입력 데이터 크기 확인
input_shape = X_train.shape[1]
# 모델 구성
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(input_shape,)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
# 모델 컴파일
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 모델 학습
model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test))
# 모델 평가
test_loss, test_acc = model.evaluate(X_test, y_test)
print('Test accuracy:', test_acc)
# TensorFlow Lite 변환
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
# TensorFlow Lite 모델 저장
with open('voice_recognition_model.tflite', 'wb') as f:
f.write(tflite_model)
def representative_dataset_gen():
for i in range(len(X_train)):
yield [X_train[i].astype(np.float32)]
# TensorFlow Lite 변환 및 완전 정수 양자화
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
tflite_quant_model = converter.convert()
# 완전 정수 양자화된 TensorFlow Lite 모델 저장
with open('voice_recognition_model_quant.tflite', 'wb') as f:
f.write(tflite_quant_model)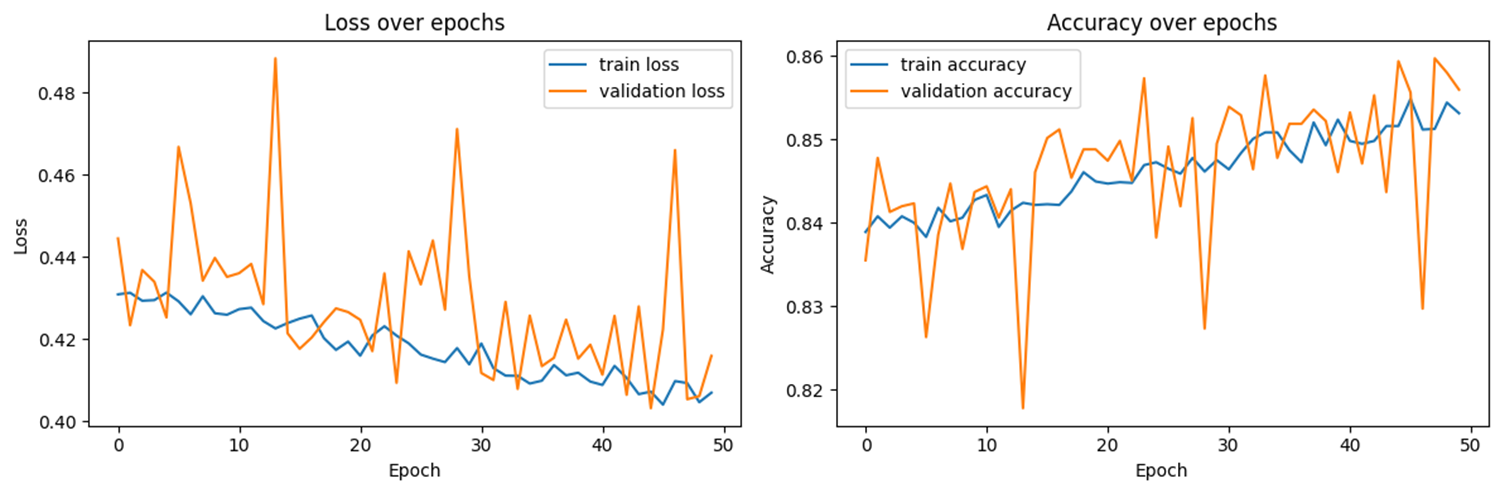
This is the result of training.
Because the data set itself is not sufficient, it shows an unstable learning situation. In the case of loss, the accuracy decreases due to sudden surges, but it appears to be learning overall.
Considering that there are three types of classification and insufficient data, I am satisfied with the higher accuracy than expected.
WakeWord_Detection.ino
#include <TensorFlowLite.h>
#define ARDUINO_EXCLUDE_CODE
#include "tensorflow/lite/micro/kernels/all_ops_resolver.h"
#include "tensorflow/lite/micro/micro_error_reporter.h"
#include "tensorflow/lite/micro/micro_interpreter.h"
#include "tensorflow/lite/schema/schema_generated.h"
#include "tensorflow/lite/version.h"
#undef ARDUINO_EXCLUDE_CODE
#include "voice_recognition_model.h" // 변환된 모델 파일 포함
#include <fix_fft.h>
// 모델 관련 상수 정의
const int kTensorArenaSize = 4 * 1024; // 텐서 아레나 크기 증가
const int kNumInputs = 1;
const int kNumOutputs = 1;
const int kInputFrames = 4;
const int kInputShape[4] = {1, 257, kInputFrames, 1};
const int kOutputSize = 3;
const int analogSensorPin = 26;
const int ledPin = LED_BUILTIN;
const int sampleRate = 1000;
const int sampleTime = 1;
const int totalSamples = sampleRate * sampleTime;
int16_t vReal[totalSamples];
int16_t vImag[totalSamples];
unsigned long startTime;
// 텐서 아레나 메모리 할당
uint8_t tensor_arena[kTensorArenaSize];
// 오디오 입력 버퍼
float audio_buffer[257 * kInputFrames];
int audio_buffer_index = 0;
// 모델 추론 함수
String inference(float* input_data) {
// 에러 리포터 설정
tflite::MicroErrorReporter micro_error_reporter;
tflite::ErrorReporter* error_reporter = µ_error_reporter;
// 플랫버퍼 모델 포인터 설정
const tflite::Model* model = ::tflite::GetModel(voice_recognition_model_tflite);
if (model->version() != TFLITE_SCHEMA_VERSION) {
return "Model schema mismatch";
}
// 모델 연산자 설정
tflite::ops::micro::AllOpsResolver resolver;
// 인터프리터 생성
tflite::MicroInterpreter interpreter(model, resolver, tensor_arena, kTensorArenaSize, error_reporter);
// 텐서 할당
interpreter.AllocateTensors();
// 입력 텐서 포인터 얻기
TfLiteTensor* input = interpreter.input(0);
// 입력 데이터 복사
for (int i = 0; i < 257 * kInputFrames; i++) {
input->data.f[i] = input_data[i];
}
// 추론 실행
TfLiteStatus invoke_status = interpreter.Invoke();
if (invoke_status != kTfLiteOk) {
return "Invoke failed";
}
// 출력 텐서 포인터 얻기
TfLiteTensor* output = interpreter.output(0);
// 출력 결과 처리
int predicted_class = 0;
float max_probability = output->data.f[0];
for (int i = 1; i < kOutputSize; i++) {
if (output->data.f[i] > max_probability) {
predicted_class = i;
max_probability = output->data.f[i];
}
}
// 결과 반환
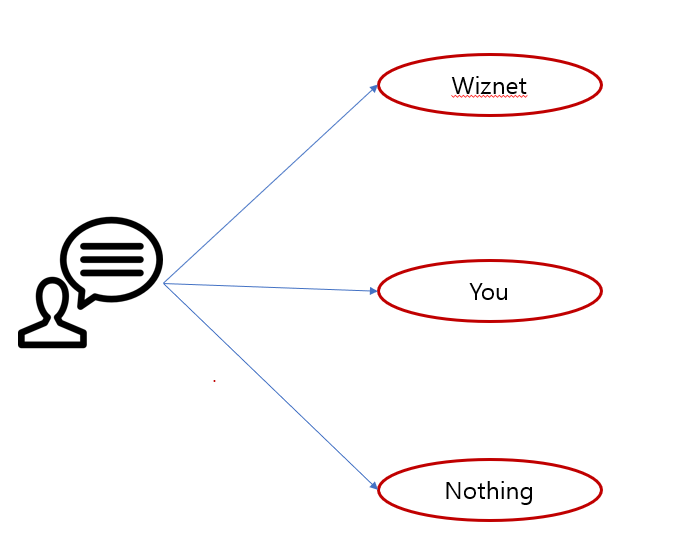
if (predicted_class == 0) {
return "Nothing";
} else if (predicted_class == 1) {
return "WIZnet";
} else if (predicted_class == 2) {
return "You";
}
return "Unknown";
}
void fft_wrapper(int16_t* vReal, int16_t* vImag, int n, int inverse) {
fix_fft((char*)vReal, (char*)vImag, n, inverse);
}
void setup() {
// 시리얼 통신 초기화
Serial.begin(9600);
pinMode(ledPin, OUTPUT);
}
void loop() {
Serial.print("PLEASE Recognized word: ");
// 오디오 입력 받기
if (audio_buffer_index < 257 * kInputFrames) {
digitalWrite(ledPin, HIGH);
startTime = millis();
for (int i = 0; i < totalSamples; i++) {
vReal[i] = analogRead(analogSensorPin);
vImag[i] = 0; // 허수부는 0으로 초기화
while (millis() < startTime + (i * 1000.0 / sampleRate));
}
digitalWrite(ledPin, LOW);
// FFT 계산
fft_wrapper(vReal, vImag, 10, 0);
// FFT 결과를 audio_buffer에 저장
for (int i = 0; i < totalSamples / 2; i++) {
double magnitude = sqrt(vReal[i] * vReal[i] + vImag[i] * vImag[i]);
audio_buffer[audio_buffer_index++] = magnitude;
}
}
// 오디오 버퍼가 가득 찼을 때 추론 수행
if (audio_buffer_index >= 257 * kInputFrames) {
// 추론 실행
String result = inference(audio_buffer);
// 결과 출력
Serial.print("Recognized word: ");
Serial.println(result);
// 오디오 버퍼 초기화
audio_buffer_index = 0;
}
delay(500); // 500밀리초 대기
}
Result
https://www.youtube.com/shorts/CfJKs5EapFk